

{kind=link}
(Dragon Claw/Shuttersock)
The GTC 2025 present final week could have been the time of AI Agent’s rupture, however central expertise behind him has improved silently behind the scene. This progress is being traced by means of a sequence of coding reference factors, reminiscent of Swe Bench and Gaia, which makes some consider that AI brokers are on the cusp of one thing large.
Not so way back that the code generated by AI will not be thought-about ample for its implementation. The SQL code could be too detailed or the Python code could be flawed or insecure. Nevertheless, this example has modified significantly in latest months, and as we speak’s fashions are producing extra code for patrons day-after-day.
The reference factors present a great way to measure to what extent the agentic AI has arrived within the software program engineering area. Probably the most well-liked reference factors, referred to as Swe-Bench, was created by researchers from Princeton College to measure how effectively LLMS as LLMS Purpose‘Slama and AnthropicClaude can resolve the frequent software program engineering challenges. The reference level makes use of GITHUB As a wealthy useful resource of Python software program errors in 16 repositories, and supplies a mechanism to measure how effectively the AI brokers primarily based on LLM may be resolved.
When the authors introduced their position, “Bench Swe: Can language fashions resolve Github issues in the true world?” To the Worldwide Convention on Studying Representations (ICLR) in October 2023, the LLM didn’t work at a excessive stage. “Our evaluations present that each the newest patented fashions and our tuned SWE-Llama mannequin can resolve solely the best issues,” the authors wrote within the abstract. “The perfect efficiency mannequin, Claude 2, can resolve just one.96% of issues.”
That modified rapidly. At present, the Swe-Bench classification desk reveals that the higher rating mannequin solved 55% of the Swe-Bench Lite coding issues, which is a subset of the reference level designed to make the analysis inexpensive and extra accessible.
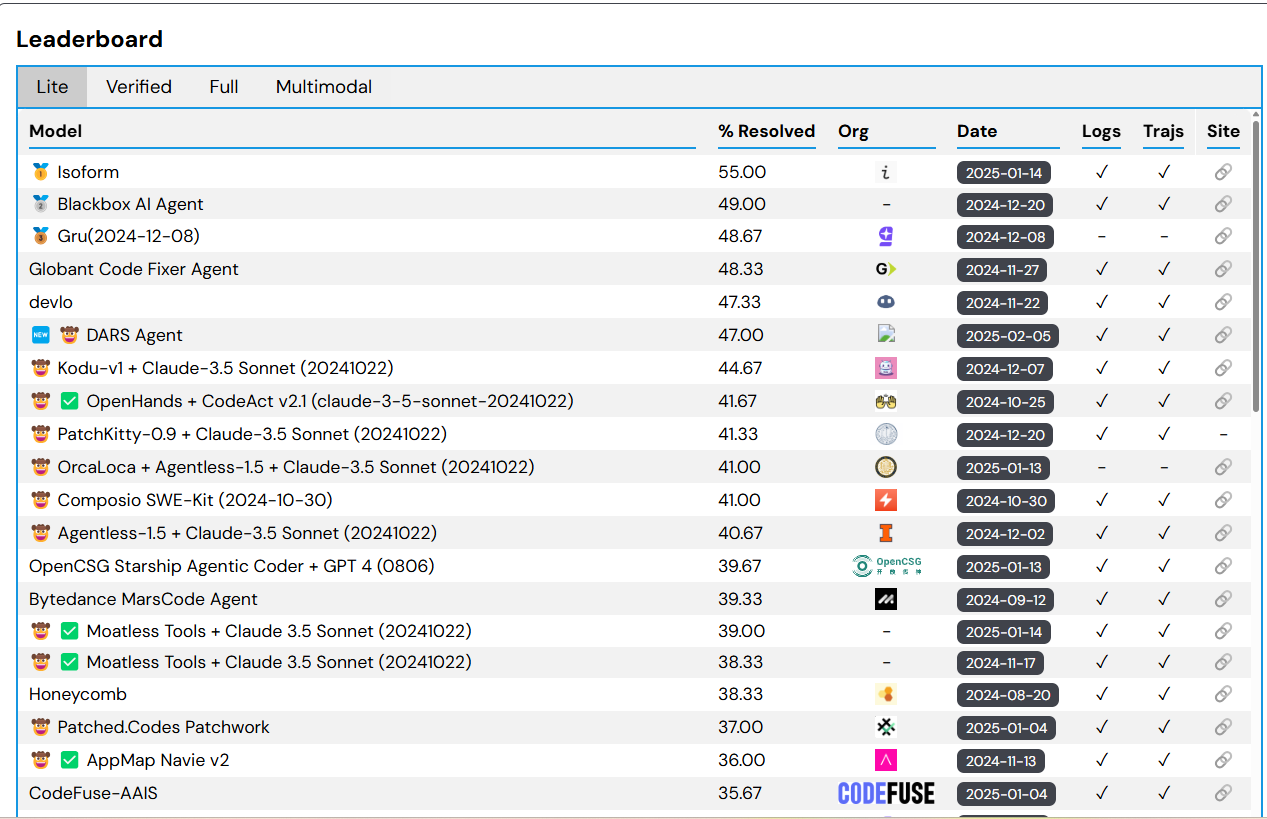
Swe-Bench measures the AI brokers to unravel GITHUB issues. You’ll be able to see present leaders at https://www.swebench.com/
Hug face Collect a reference level for normal’s attendees, referred to as Gaiawhich measures the flexibility of a mannequin in a number of areas, together with reasoning, administration of multimodality modality, internet navigation and competitors typically for the usage of instruments. Gaia’s checks will not be ambiguous and difficult, reminiscent of counting the variety of birds in a 5 -minute video.
A yr in the past, the higher rating at stage 3 of the GAIA check was round 14, based on Sri Ambati, CEO and co -founder of H2O.AI. At present, an H2O.AI -based mannequin primarily based on Claude 3.7 Sonnet has the higher normal rating, roughly 53.
“So precision is actually rising very quick,” stated Ambati. “We’re not fully there, however we’re on that path.”
The H2O.AI software program is concerned in one other reference level that measures the SQL technology. Fowl, which suggests Massive Bench for the analysis of textual content textual content to SQL on a big scale, measures how effectively AI fashions can analyze pure language in SQL.
When Fowl debuted in Could 2023, the upper rating mannequin, COT+ChatgPT, demonstrated roughly 40% precision. A yr in the past, the upper scoring AI mannequin, exsl+Granite-20b Code, was primarily based on the IBM granite AI mannequin and had an accuracy of roughly 68%. That was fairly beneath the capability of human efficiency, which measures birds in roughly 92%. The present fowl classification plate reveals an H2O.AI of AT&T mannequin as a pacesetter, with a 77percentprecision price.
The fast progress within the technology of an honest pc code has led some influential leaders, reminiscent of Nvidia CEO and co -founder Jensen Huang and Anthropic The co -founder and CEO Dario Amodei, to make daring predictions on the place we’ll quickly discover ourselves.
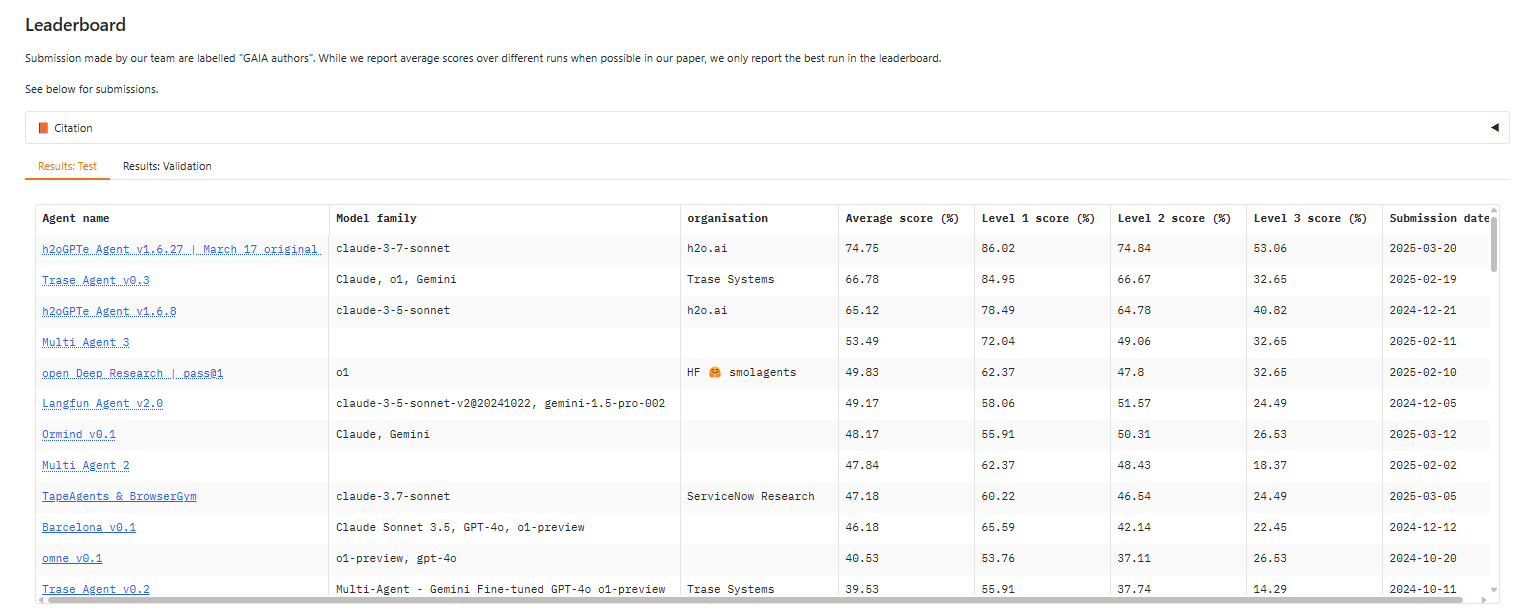
Gaia measures the flexibility of AI brokers to deal with a sequence of duties. You’ll be able to see the present leaders board at https://huggingface.co/areas/gaia-benchmark/leaderboard
“We’re not removed from being a world, I believe we might be there in three to 6 months, the place AI is writing 90 % of the code,” Amodei He stated earlier this month. “After which, in twelve months, we may be in a world the place AI is actually writing the complete code.”
Throughout his key GTC25 be aware final week, Huang shared his imaginative and prescient of the way forward for agent computing. In his opinion, we rapidly method a world the place AI factories generate and execute software program primarily based on human entries, not like people who write software program to get better and manipulate knowledge.
“Whereas previously we wrote the software program and executed it on computer systems, sooner or later, computer systems will generate tokens for software program,” Huang stated. “And so, the pc has turn out to be a tokens generator, not a file restoration. (We’ve got gone) of pc science primarily based on the restoration of generative computing.”
Others are having a extra pragmatic imaginative and prescient. Anupam Datta, the principle analysis scientist of Snowflake and the chief of the Snowflake AI AI analysis staff applauds enchancment in SQL technology. For instance, Snowflake says that the SQL textual content technology precision price of its Cortex agent is 92%. Nevertheless, Datta doesn’t share Amodei’s opinion that computer systems will roll their very own code by the top of the yr.
“My opinion is that coding brokers in sure areas, as a textual content to SQL, I believe they’re turning into actually good,” Datta stated in GTC25 final week. “Sure different areas are extra assistants that assist a programmer to be quicker. The human will not be but out of the circuit.”
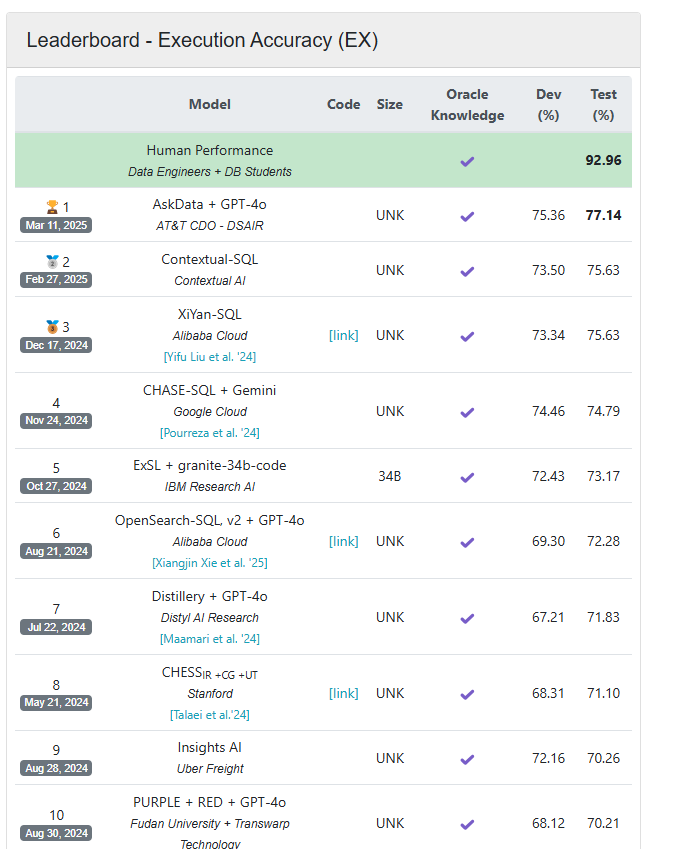
The fowl measures the textual content capability to SQL of the AI brokers. You’ll be able to entry the present leaderbord at https://bird-bench.github.io/
The programmer’s productiveness would be the nice winner due to the coding of co -drivers and agent methods, he stated. We’re not removed from a world the place agentic will generate the primary draft, he stated, after which people will enter and refine it and enhance it. “There might be nice earnings in productiveness,” Datta stated. “Subsequently, the affect might be very important, solely with co -pilot.”
Ambati de H2O.AI additionally believes that software program engineers will work in shut collaboration with AI. Even as we speak’s greatest coding brokers introduce “refined errors”, so folks nonetheless have to see the code, he stated. “It’s nonetheless a set of fairly vital abilities.”
An space that’s nonetheless fairly inexperienced is the semantic layer, the place pure language is translated into industrial context. The issue is that the English language may be ambiguous, with a number of meanings of the identical phrase.
“A part of that is to know the semantics layer of the consumer scheme, the metadata,” stated Ambati. “That piece continues to be being constructed. That ontology stays a information of area.”
Hallucinations are additionally an issue, as is the potential for an AI mannequin to go away the rails and say or do dangerous issues. These are all areas of concern that firms reminiscent of Anthrope, Nvidia, H2O.AI and Snowflake are working to mitigate. However because the central capacities of technology AI enhance, the variety of causes to not put AI brokers in manufacturing.
Associated articles:
Speed up the productiveness of the Agent with enterprise frames
NVIDIA PREPS for 100X arises in inference work masses, due to the reasoning of AI brokers
Reporter Pocket book: Hype and Glory in Nvidia GTC 2025