

{kind=link}
Recognition of human motion. Using time sequence from cell and wearable units is often used as key context data for numerous purposes, from well being standing monitoring to sports activities exercise evaluation and consumer behavior research. Nonetheless, amassing large-scale movement time sequence knowledge stays difficult as a result of safety both privateness considerations. Within the area of movement time sequence, the dearth of knowledge units and an efficient pre-training process makes it tough to develop related fashions that may function on restricted knowledge. Current fashions sometimes carry out coaching and testing on the identical knowledge set, and have problem generalizing throughout totally different knowledge units as a result of three distinctive challenges throughout the movement time sequence downside area: FirstInserting units in numerous places on the physique (resembling on the wrist or leg) generates very totally different knowledge, making it tough to make use of a mannequin skilled for one location elsewhere. SecondSince units could be held in numerous orientations, it’s problematic as a result of fashions skilled with a tool in a single place typically battle when the gadget is held in another way. LastlyTotally different knowledge units typically deal with various kinds of actions, making it tough to check or mix the information successfully.
Standard classification of movement time sequence depends on separate classifiers for every knowledge set, utilizing strategies resembling statistical function extraction, cnn, RNNand fashions of care. Common function fashions resembling TimesNet and SHARE they level to the flexibility of the duties, however require coaching or testing on the identical knowledge set; subsequently, they restrict adaptability. Self-supervised studying helps in illustration studying, though generalization throughout a number of knowledge units stays a problem. Pre-trained fashions like Picture hyperlink and IMU2CLIP take into account movement and textual content knowledge, however are restricted by device-specific coaching. Strategies utilizing giant language fashions (LLM) are cue-based, however have problem recognizing complicated actions as they aren’t skilled on uncooked movement time sequence and have problem precisely recognizing complicated actions.
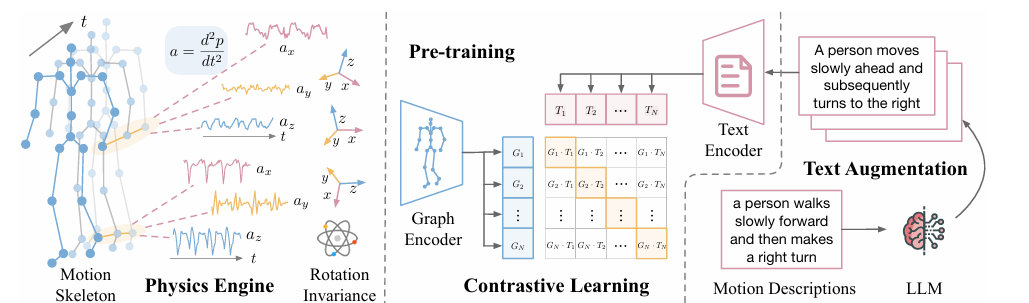
A gaggle of researchers from College of California at San Diego, Amazonas, and Qualcomm proposed UniMTS as the primary unified pre-training process for movement time sequence that generalizes throughout numerous elements and latent gadget actions. UniMTS makes use of a contrastive studying framework to hyperlink movement time sequence knowledge with wealthy textual content descriptions of huge language fashions (LLMs). This helps the mannequin perceive the that means behind totally different actions and permits it to generalize throughout numerous actions. For giant-scale pre-training, UniMTS generates movement time sequence knowledge based mostly on current detailed skeletal knowledge, protecting a number of physique components. The generated knowledge is then processed utilizing graph networks to seize spatial and temporal relationships throughout totally different gadget places, serving to the mannequin generalize to knowledge from totally different gadget places.
The method begins by creating movement knowledge from the skeleton’s actions and adjusting it for various orientations. It additionally makes use of a graphical encoder to know how the joints join so it might probably work nicely on totally different units. Textual content descriptions are improved utilizing giant language fashions. To create movement knowledge, it calculates the velocities and accelerations of every joint whereas contemplating their positions and orientations, including noise to imitate the errors of real-world sensors. To deal with inconsistencies in gadget orientation, UniMTS makes use of knowledge augmentation to create random orientations throughout pre-training. This technique takes under consideration variations in gadget positions and axis configuration. By aligning movement knowledge with textual content descriptions, the mannequin can adapt nicely to totally different orientations and kinds of exercise. For coaching, UniMTS employs rotation-invariant knowledge augmentation to deal with gadget positioning variations. It was examined in HumanML3D knowledge set and 18 different real-world movement time sequence reference knowledge units, specifically with improved efficiency of 340% in zero shot configuration, 16.3% within the few photographs setting, and 9.2% within the full-shot configuration, in comparison with the respective best-performing baselines. Mannequin efficiency was in comparison with baselines resembling Picture hyperlink and IMU2CLIP. The outcomes confirmed that UniMTS outperformed different fashions, particularly in zero-shot environments, based mostly on statistical exams that confirmed vital enhancements.
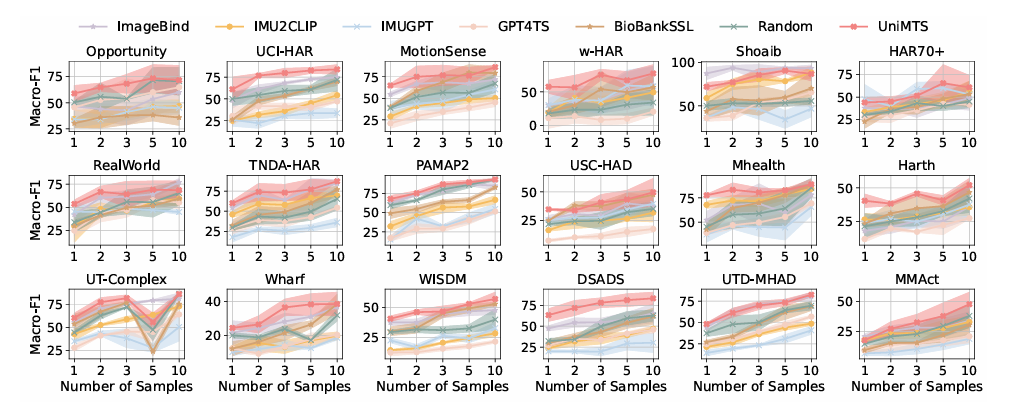
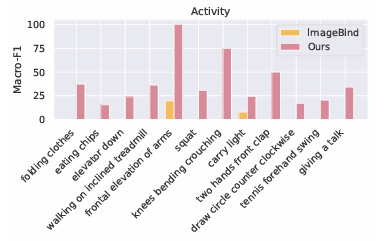
In conclusion, the proposed pretrained mannequin. UniMTS relies solely on physics-simulated knowledge, however reveals outstanding generalization throughout various real-world movement time sequence datasets that includes totally different gadget places, orientations, and actions. Whereas making the most of the efficiency of conventional strategies, UniMTS additionally has some limitations. In a broader sense, this pre-trained movement time sequence classification mannequin can act as a possible basis for upcoming analysis within the area of human movement recognition.
have a look at the Paper, GitHuband Mannequin in hugging face. All credit score for this analysis goes to the researchers of this mission. Additionally, remember to comply with us on Twitter and be a part of our Telegram channel and LinkedIn Grabove. For those who like our work, you’ll love our data sheet.. Remember to hitch our SubReddit over 55,000ml.
(Sponsorship alternative with us) Promote your analysis/product/webinar to over 1 million month-to-month readers and over 500,000 group members
Divyesh is a Consulting Intern at Marktechpost. He’s pursuing a BTech in Agricultural and Meals Engineering from the Indian Institute of Know-how Kharagpur. He’s a knowledge science and machine studying fanatic who desires to combine these main applied sciences in agriculture and clear up challenges.