

{kind=link}
Introduction
Backpropagation has been the driving drive behind the deep studying revolution. Now we have come a good distance with advances similar to:
- New layers similar to Convolutional Neural Networks, Recurrent Neural Networks, Transformers.
- New coaching paradigms similar to tuning, switch studying, self-supervised studying, contrastive studying, and reinforcement studying.
- New optimizers, regularizers, augmentations, loss capabilities, frameworks and plenty of extra…
Nonetheless, the Abstraction and Reasoning Corpus (ARC) dataset, created greater than 5 years in the past, has stood the check of quite a few architectures however has by no means modified. It stays probably the most troublesome knowledge units, the place even the very best fashions can’t surpass human-level accuracy. This was a sign that true AGI remains to be far out of attain.
Final week, a brand new paper “The Stunning Effectiveness of Take a look at-Time Coaching for Summary Reasoning” pushed a comparatively novel method, reaching a brand new stage of accuracy on the ARC knowledge set that has the deep studying group excited. just like how AlexNet did it 12 years in the past.
TTT was invented 5 years in the past, the place coaching happens on only a few samples (normally one or two) just like the check knowledge level. The mannequin can replace its parameters primarily based on these examples, hyper-fitting to simply these knowledge factors.
TTT is analogous to remodeling a normal practitioner right into a surgeon who’s now tremendous specialised in solely Coronary heart valve replacements.
On this publish, we’ll study what TTT is, how we are able to apply it in numerous duties and talk about the benefits, disadvantages and implications of utilizing TTT in real-world eventualities.
What’s trial time coaching?
People are very adaptable. Two studying phases observe for any activity: a normal studying section that begins from beginning and a task-specific studying section, usually generally known as activity orientation. Equally, TTT enhances pretraining and tuning as a second section of studying that happens throughout inference.
Merely put, Take a look at Time Coaching entails cloning a mannequin skilled in the course of the testing section and becoming it on knowledge factors just like the information you wish to make an inference about. To divide the method into steps, throughout inference, given a brand new check knowledge level to deduce, we carry out the next actions:
- clone the mannequin (normal goal),
- acquire knowledge factors from the coaching set which might be closest to the check level, both via some prior data or by incorporating similarities,
- create a smaller coaching knowledge set with inputs and targets utilizing the information from the earlier step,
- determine on a loss perform and prepare the cloned mannequin on this small knowledge set,
- use the up to date clone mannequin to foretell that check knowledge level.
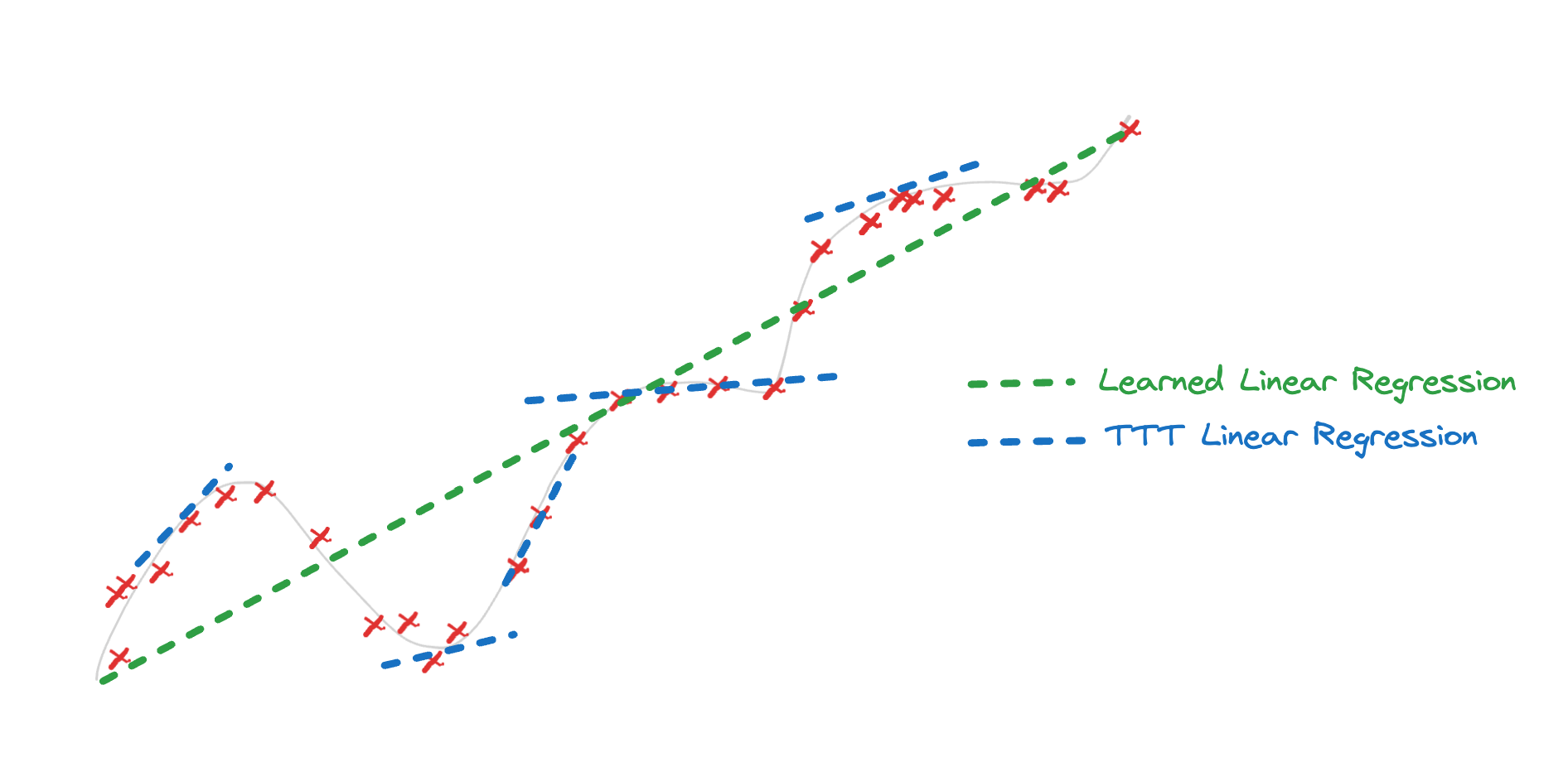
As a easy instance, you possibly can take a skilled linear regression mannequin, replace the slope of a set of factors within the neighborhood of the check level, and use it to make extra correct predictions.
Okay-Nearest Neighbors is an excessive instance of a TTT course of the place the one coaching that’s accomplished is throughout testing time.
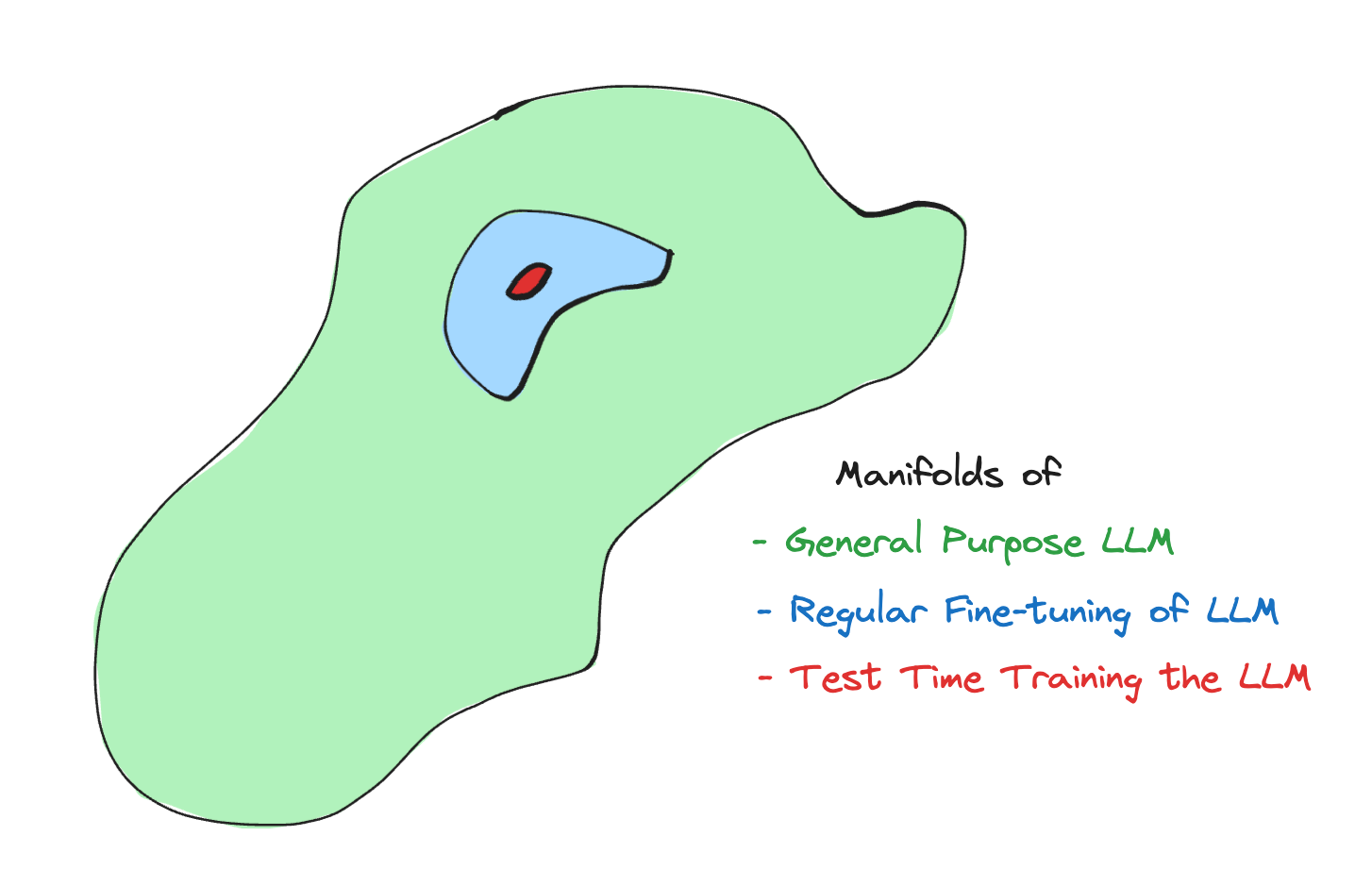
Within the LLM area, TTT is particularly helpful when the duties are advanced and out of doors of what an LLM has seen earlier than.
Studying in context, transient prompts, chain-of-thought reasoning, and augmented retrieval technology have been requirements for bettering LLMs throughout inference. These strategies enrich the context earlier than arriving at a last reply, however they fail in a single facet: the mannequin doesn’t adapt to the brand new atmosphere on the time of testing. With TTT, we are able to make the mannequin study new ideas that will in any other case unnecessarily seize a considerable amount of knowledge.
The ARC knowledge set is right for this paradigm, as every knowledge pattern is a group of quick examples adopted by a query that may solely be solved utilizing the given examples, just like how the SAT exams require you to search out the next diagram in a sequence.
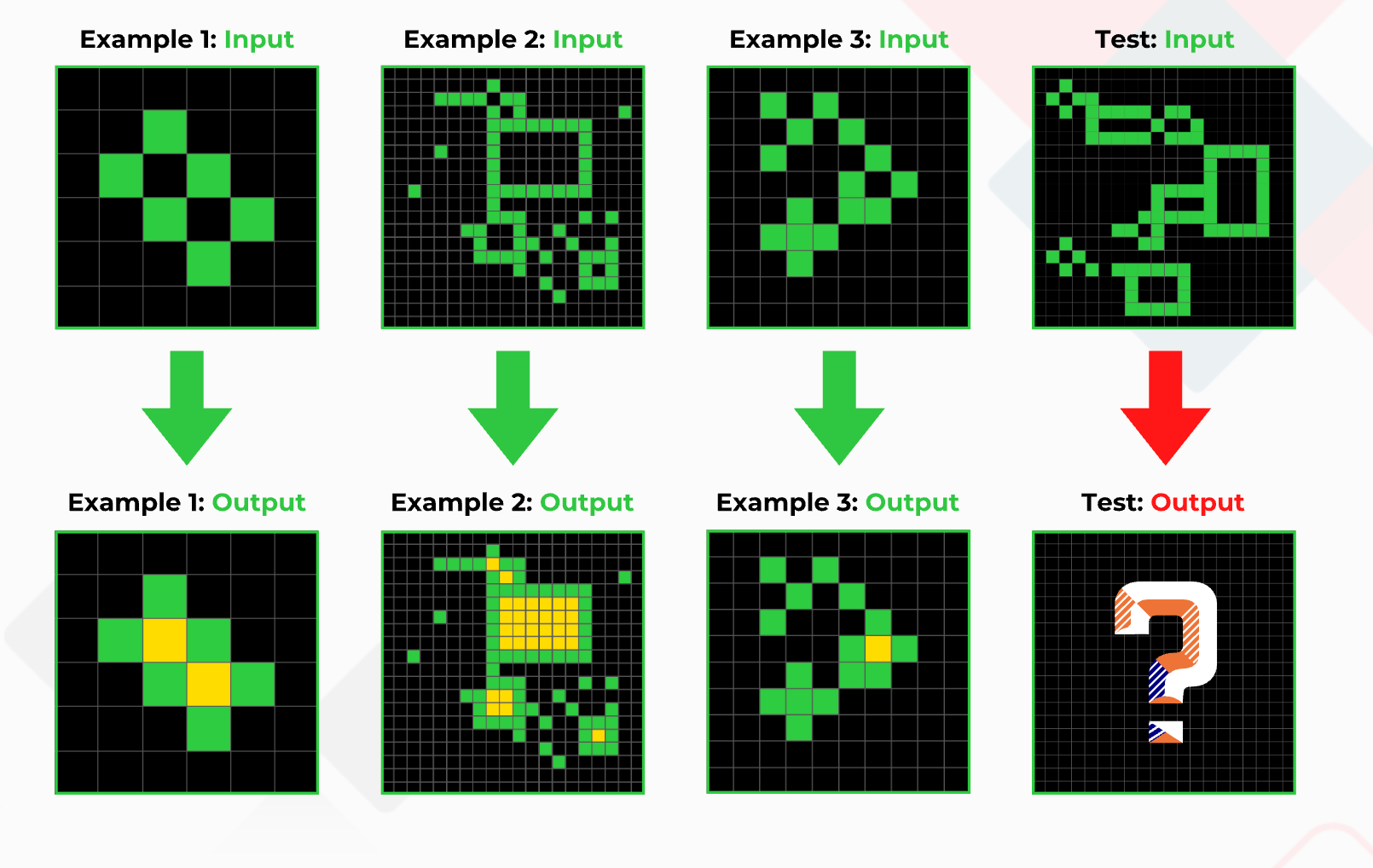
As proven within the picture above, the primary three examples can be utilized to coach in the course of the check time and predict within the fourth picture.
How one can carry out TTT
The brilliance of the TTT lies in its simplicity; extends studying to the testing section. Due to this fact, all customary coaching strategies will be utilized right here, however there are sensible features to think about.
Since coaching is computationally costly, TTT provides extra overhead since, in concept, coaching is required for every inference. To mitigate this value, think about:
- Parameter Environment friendly High quality Tuning (PEFT): Throughout LLM coaching, coaching with LoRA is significantly cheaper and sooner. It’s at all times advisable to coach solely on a small subset of layers, as in PEFT, somewhat than performing a full mannequin becoming.
def test_time_train(llm, test_input, nearest_examples, loss_fn, OptimizerClass):
lora_adapters = initialize_lora(llm)
optimizer = OptimizerClass(lora_adapters, learning_rate)
new_model = merge(llm, lora_adapters)
for nearest_example_input, nearest_example_target in nearest_examples:
nearest_example_prediction = new_model(nearest_example_input)
loss = loss_fn(nearest_example_prediction, nearest_example_target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
predictions = new_model(test_input)
return predictionsPsuedocode for coaching in testing instances with LLM
- Switch studying: Throughout standard switch studying, a brand new activity header will be changed/added and the mannequin skilled.
def test_time_train(base_model, test_input, nearest_examples, loss_fn, OptimizerClass):
new_head = clone(base_model.head)
optimizer = OptimizerClass(new_head, learning_rate)
for nearest_example_input, nearest_example_target in nearest_examples:
nearest_example_feature = base_model.spine(nearest_example_input)
nearest_example_prediction = new_head(nearest_example_feature)
loss = loss_fn(nearest_example_prediction, nearest_example_target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
test_features = base_model.spine(test_input)
predictions = new_head(test_features)
return predictionsPsuedocode for test-time coaching with standard switch studying
- Embed Reuse: Hold monitor of what inferences had been made, that’s, what LoRAs had been used. Throughout inference, if the embedding of a brand new knowledge level is shut sufficient to the prevailing ones, an present LoRA/Job-Head might be reused.
- Take a look at Time Will increase (TTA): TTA clones the inference picture and applies augmentations. The typical of all predictions offers a extra strong outcome. In TTT, this could enhance efficiency by enriching the coaching knowledge.
Actual world makes use of
- medical analysis: Adjusting normal diagnostic fashions for particular affected person situations or uncommon illnesses with restricted knowledge.
- Personalised schooling: Adapt an academic AI to a pupil’s studying model utilizing particular examples.
- Customer support chatbots: Enhance chatbots for particular queries by coaching on particular subjects throughout a session.
- Autonomous Autos: Adapt automobile management fashions to native visitors patterns.
- Fraud detection: Specialised fashions for a particular enterprise or uncommon transaction patterns.
- Evaluation of authorized paperwork: Adaptation of fashions to interpret authorized precedents of particular instances.
- Artistic content material technology: Customise LLMs to generate contextually related content material, similar to adverts or tales.
- Doc knowledge extraction: Adjusting particular templates to extract knowledge extra precisely.
Benefits
- Hyperspecialization: Helpful for uncommon knowledge factors or one-off duties.
- Information effectivity: High quality tuning with minimal knowledge for particular eventualities.
- Flexibility: Improves generalization throughout a number of specializations.
- Area adaptation: Addresses distribution drift throughout lengthy deployments.
Disadvantages
- Computational value: Extra coaching in inference will be expensive.
- Latency: Not appropriate for real-time LLM functions with present know-how.
- Danger of maladaptation: Making changes to irrelevant examples can degrade efficiency.
- Danger of poor efficiency in easy fashions: TTT shines when the mannequin has a lot of parameters to study and the information throughout testing time has a excessive diploma of variation. While you attempt to apply TTT with easy fashions like linear regression, it is going to solely overfit to native knowledge and that is nothing greater than overfitting a number of fashions utilizing KNN pattern knowledge.
- Complicated integration: Requires cautious design to combine coaching into inference and monitor a number of fashions.
TTT is a promising software, however with vital overhead and dangers. When used properly, it could possibly enhance mannequin efficiency in difficult eventualities past what standard strategies can obtain.