

{kind=link}
Neural networks have change into elementary instruments in laptop imaginative and prescient, NLP, and plenty of different fields, providing capabilities to mannequin and predict complicated patterns. The coaching course of is on the core of neural community performance, the place community parameters are iteratively adjusted to attenuate error utilizing optimization strategies resembling gradient descent. This optimization happens in a high-dimensional parameter house, making it tough to decipher how the preliminary parameter settings affect the ultimate educated state.
Though progress has been made within the research of those dynamics, doubts nonetheless stay about the dependence of the ultimate parameters on their preliminary values and the function of enter information stay to be answered. Researchers search to find out whether or not particular initializations result in distinctive optimization paths or whether or not transformations are predominantly ruled by different elements resembling structure and information distribution. This understanding is crucial to design extra environment friendly coaching algorithms and enhance the interpretability and robustness of neural networks.
Earlier research have provided insights into the low-dimensional nature of neural community coaching. Analysis exhibits that parameter updates typically occupy a comparatively small subspace of the general parameter house. For instance, projections of gradient updates onto randomly oriented low-dimensional subspaces are likely to have minimal results on the ultimate community efficiency. Different research have noticed that almost all parameters stay near their preliminary values throughout coaching and updates are sometimes roughly low vary over brief intervals. Nevertheless, these approaches fail to totally clarify the connection between initialization and last states or how particular information buildings affect these dynamics.
EleutherAI researchers launched a novel framework for analyzing neural community coaching through Jacobian matrix to handle the above points. This methodology examines the Jacobian of the educated parameters with respect to their preliminary values, capturing how initialization shapes the ultimate states of the parameters. By making use of singular worth decomposition to this matrix, the researchers decomposed the coaching course of into three distinct subspaces:
- chaotic subspace
- Bulk subspace
- secure subspace
This decomposition supplies an in depth understanding of the affect of initialization and information construction on coaching dynamics, providing a brand new perspective on the optimization of neural networks.
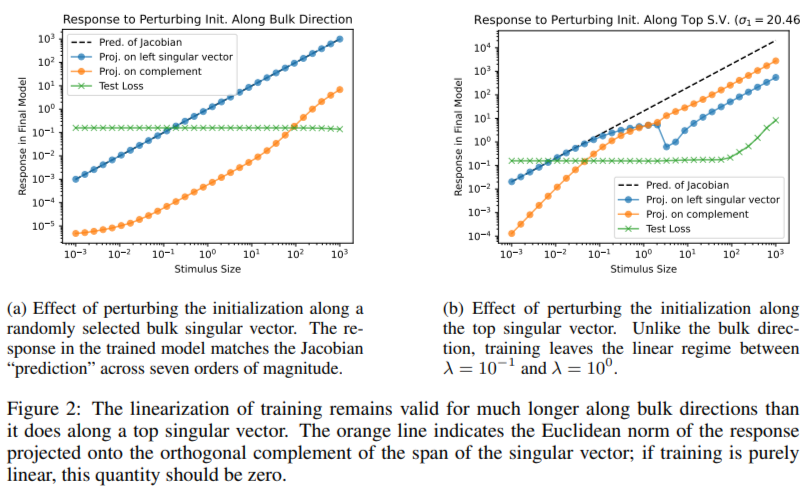
The methodology includes linearizing the coaching course of across the preliminary parameters, permitting the Jacobian matrix to map how small initialization perturbations propagate throughout coaching. Singular worth decomposition revealed three distinct areas within the Jacobian spectrum. The chaotic area, comprising roughly 500 singular values considerably bigger than one, represents instructions the place parameter adjustments are amplified throughout coaching. The large area, with round 3000 singular values shut to at least one, corresponds to dimensions the place the parameters stay just about unchanged. The secure area, with roughly 750 singular values lower than one, signifies instructions the place adjustments are damped. This structured decomposition highlights the various affect of parameter house instructions on coaching progress.
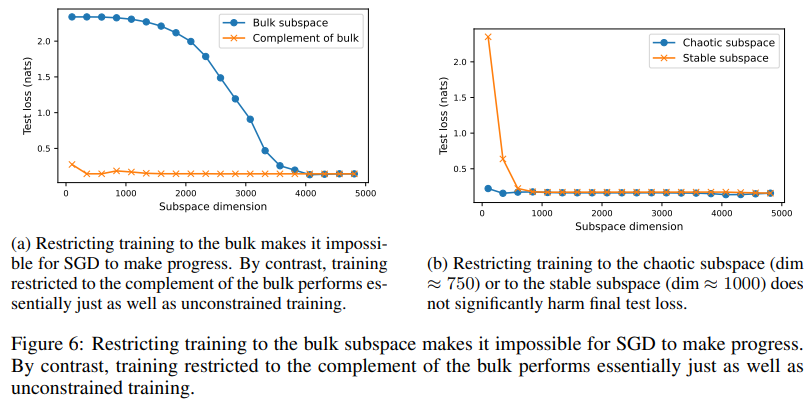
In experiments, the chaotic subspace shapes the optimization dynamics and amplifies parameter perturbations. Steady subspace ensures smoother toe-in by dampening shifts. Apparently, regardless of occupying 62% of the parameter house, the large subspace has minimal affect on habits throughout the distribution, however considerably impacts predictions for information exterior the distribution. For instance, perturbations alongside bulk instructions go away take a look at set predictions largely unchanged, whereas these in chaotic or secure subspaces can alter the outcomes. Proscribing coaching to the majority subspace made gradient descent ineffective, whereas coaching on chaotic or secure subspaces achieved comparable efficiency to unconstrained coaching. These patterns have been constant throughout totally different initializations, loss capabilities, and information units, demonstrating the robustness of the proposed framework. Experiments with a multilayer perceptron (MLP) with a hidden layer of width 64, educated on the UCI Digits dataset, confirmed these observations.
A number of conclusions emerge from this research:
- The chaotic subspace, comprising roughly 500 singular values, amplifies parameter perturbations and is instrumental in shaping the optimization dynamics.
- With round 750 singular values, the secure subspace successfully buffers perturbations, contributing to clean and secure coaching convergence.
- The large subspace, which represents 62% of the parameter house (roughly 3000 singular values), stays just about unchanged throughout coaching. It has minimal influence on habits throughout the distribution, however vital results on predictions exterior the distribution.
- Perturbations alongside chaotic or secure subspaces alter the community outputs, whereas large perturbations go away take a look at predictions largely unaffected.
- Proscribing coaching to bulk subspace makes optimization ineffective, whereas coaching restricted to chaotic or secure subspaces has efficiency corresponding to full coaching.
- The experiments persistently demonstrated these patterns on totally different information units and initializations, highlighting the generality of the findings.
In conclusion, this research presents a framework for understanding the dynamics of neural community coaching by decomposing parameter updates into chaotic, secure, and large subspaces. It highlights the intricate interaction between initialization, information construction, and parameter evolution, offering invaluable insights into how coaching proceeds. The outcomes reveal that the chaotic subspace drives optimization, the secure subspace ensures convergence, and the large subspace, though massive, has minimal influence on the distribution habits. This nuanced understanding challenges standard assumptions about uniform parameter updates. Supplies sensible methods to optimize neural networks.
Confirm he Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, do not forget to comply with us on Twitter and be a part of our Telegram channel and LinkedIn Grabove. Do not forget to affix our SubReddit over 60,000 ml.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of synthetic intelligence for social good. Their most up-to-date endeavor is the launch of an AI media platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s technically sound and simply comprehensible to a large viewers. The platform has greater than 2 million month-to-month visits, which illustrates its recognition among the many public.