

{kind=link}
Massive multimodal (LMM) generative fashions, resembling LLaVA and Qwen-VL, excel in imaginative and prescient and language (VL) duties resembling picture captioning and visible query answering (VQA). Nonetheless, these fashions face challenges when utilized to elementary discriminative VL duties, resembling picture classification or multiple-choice VQA, which require discrete label predictions. The principle impediment is the problem in extracting helpful options from generative fashions for discriminative duties.
Present strategies for adapting LMMs to discriminative duties usually depend on speedy engineering, tuning, or specialised architectures. Though promising, these approaches are restricted by their reliance on large-scale transformation.AIno information, particular traits of the modality or lack of flexibility. To deal with this downside, a staff of researchers from Carnegie Mellon College, the College of California, Berkeley, IBM Analysis, and the MIT-IBM Watson AI Lab proposes a novel resolution: Scattered Consideration Vectors (SAV). SAVs are an adjustment-free methodology that exploits sparse attentional head activations in LMMs as options for discriminative VL duties. Impressed by the idea of useful specificity from neuroscience (how completely different elements of the mind are particular for various features) and up to date work on transformer interpretability, this methodology makes use of lower than 1% of consideration heads to extract discriminative options from efficient method. SAVs obtain state-of-the-art efficiency with only a few examples and display robustness in a wide range of duties.
Going deeper into how the tactic works, the next steps have been adopted to establish and use sparse consideration vectors, as proven in Determine 2:
- Consideration vector extraction: For a frozen LMM and a few-shot labeled information set (e.g., 20 examples per label), consideration vectors are extracted from every consideration head in every layer. Particularly, for the ultimate token of every enter sequence, the eye vector is computed as an output of the dot product consideration mechanism.
- Identification of related vectors: The discriminative capability of every consideration vector is evaluated utilizing a nearest class centroid classifier. For every class, the imply consideration vector (centroid) is calculated on the few-shot examples. Cosine similarity is calculated between the eye vector of every enter and the category centroids, and the eye heads are ranked primarily based on their classification accuracy. The most effective performing heads (e.g., high 20) are chosen because the set of sparse consideration vectors (HSAV).
- Classification utilizing SAV: Given a question enter, predictions are made utilizing the chosen sparse consideration heads. For every header in HSAV, the similarity of the question to the category centroids is calculated and the ultimate class label is decided by a majority vote throughout all headers. This strategy permits the usage of lower than 1% of the overall consideration heads, making the tactic light-weight and environment friendly.
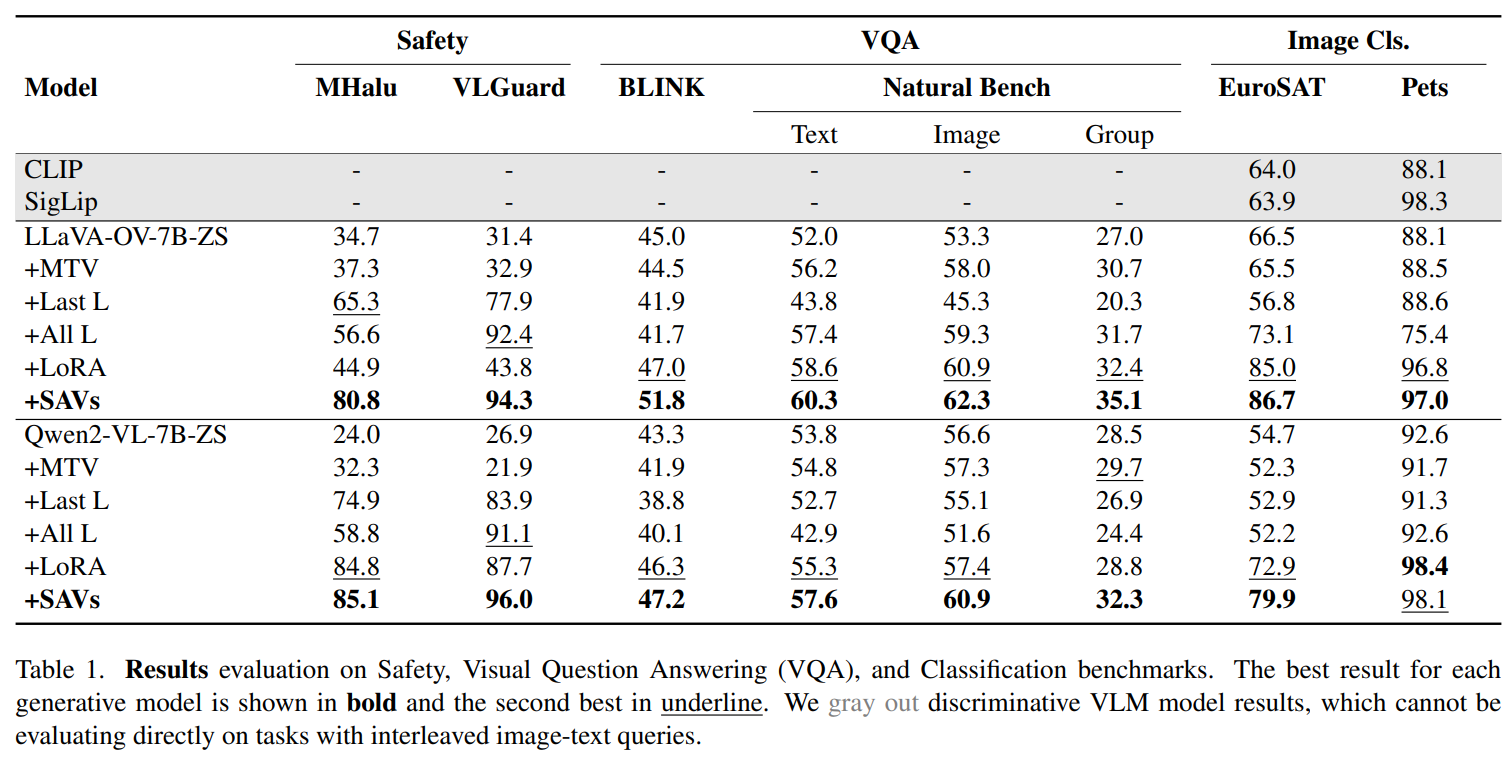
For analysis, SAVs have been examined on two state-of-the-art LMMs (LLaVA-OneVision and Qwen2-VL) and in comparison with a number of baselines, together with zero-shot (ZS) strategies, few-shot strategies, and tuning approaches resembling LoRA. . Evaluations coated a variety of VL discriminative duties. SAVs outperformed baselines in detecting hallucinations (e.g., distinguishing “hallucinate” from “not hallucinate”) and dangerous content material in information units resembling LMM-hallucination and VLGuardia. SAVs demonstrated superior efficiency on difficult information units resembling BLINK and Pure Benchthat require visible and compositional reasoning. SAVs have been additionally very efficient on information units resembling EuroSAT (satellite tv for pc picture classification) and Oxford-IIIT-Pets (Detailed classification of pet breeds). The outcomes confirmed that SAVs constantly outperformed zero-shot and few-shot baselines, closing the hole with discriminative imaginative and prescient and language fashions (VLM) resembling CLIP and SigLIP. For instance, SAVs achieved greater accuracy in safety duties and demonstrated robust efficiency in VQA and picture classification benchmarks.
Moreover, SAVs require just a few labeled examples per class, making them sensible for duties with restricted coaching information. The strategy identifies particular heads of consideration that contribute to the classification, providing details about the interior workings of the mannequin. SAVs are suited to a wide range of discriminative duties, together with these involving interleaved textual content and picture inputs. By leveraging a sparse subset of consideration heads, the tactic is computationally light-weight and scalable.
Whereas SAVs present a major development, they rely upon entry to the interior structure of the LMM. This dependency limits its applicability to open supply fashions and poses challenges for broader use. Moreover, duties resembling picture and textual content retrieval may benefit from extra granular confidence metrics than the present majority voting mechanism. Future analysis might discover enhancing SAVs for duties resembling multimodal retrieval, information compression, and have embedding for downstream functions.
Confirm he Paper and GitHub web page. All credit score for this analysis goes to the researchers of this venture. Additionally, do not forget to comply with us on Twitter and be a part of our Telegram channel and LinkedIn Grabove. Remember to hitch our SubReddit over 65,000 ml.
🚨 Advocate open supply platform: Parlant is a framework that transforms the best way AI brokers make selections in customer-facing situations. (Promoted)
Vineet Kumar is a Consulting Intern at MarktechPost. He’s presently pursuing his bachelor’s diploma from the Indian Institute of Expertise (IIT), Kanpur. He’s a machine studying fanatic. He’s obsessed with analysis and the most recent advances in Deep Studying, Pc Imaginative and prescient and associated fields.