

{kind=link}
Reinforcement studying (RL) trains brokers to make sequential selections maximizing cumulative rewards. It has varied purposes, together with robotics, video games and automation, the place brokers work together with environments to study optimum behaviors. Conventional RL strategies are divided into two classes: approaches with out fashions and fashions primarily based. Strategies with out fashions prioritize simplicity however require in depth coaching information, whereas fashions -based strategies introduce structured studying, however are computationally demanding. A rising analysis space goals to unite these approaches and develop extra versatile RL frameworks that work effectively in several domains.
A persistent problem in RL is the absence of a common algorithm able to working constantly in a number of environments with out an exhaustive parameter adjustment. Most RL algorithms are designed for particular purposes, which requires changes to work successfully in new environments. RL strategies primarily based on fashions usually show increased generalization, however on the expense of better complexity and slower execution speeds. Then again, strategies with out mannequin are simpler to implement, however typically lack effectivity once they apply to unknown duties. The event of an RL framework that integrates the strengths of each approaches with out compromising computational viability stays a key analysis goal.
A number of RL methodologies have emerged, every with compensation between efficiency and effectivity. Options primarily based on fashions similar to Dreamerv3 and TD-MPC2 have achieved substantial ends in completely different duties, however rely largely on complicated planning mechanisms and large-scale simulations. Alternate options with out mannequin, together with TD3 and PPO, provide diminished computational calls for, however require a particular area adjustment. This disparity underlines the necessity for an RL algorithm that mixes adaptability and effectivity, permitting an ideal utility in varied duties and environments.
A Meta Honest analysis group introduced MR.Q, an RL algorithm with out mannequin that includes fashions primarily based on fashions to enhance effectivity and studying generalization. Not like conventional approaches with out fashions, MR.Q takes benefit of a illustration studying part impressed by fashions primarily based on fashions, permitting the algorithm to operate successfully at completely different RL reference factors with a minimal adjustment. This strategy permits Sr.q to learn from the structured studying alerts of fashions primarily based on the time that avoids computational overload related to massive -scale planning and simulated deployment.
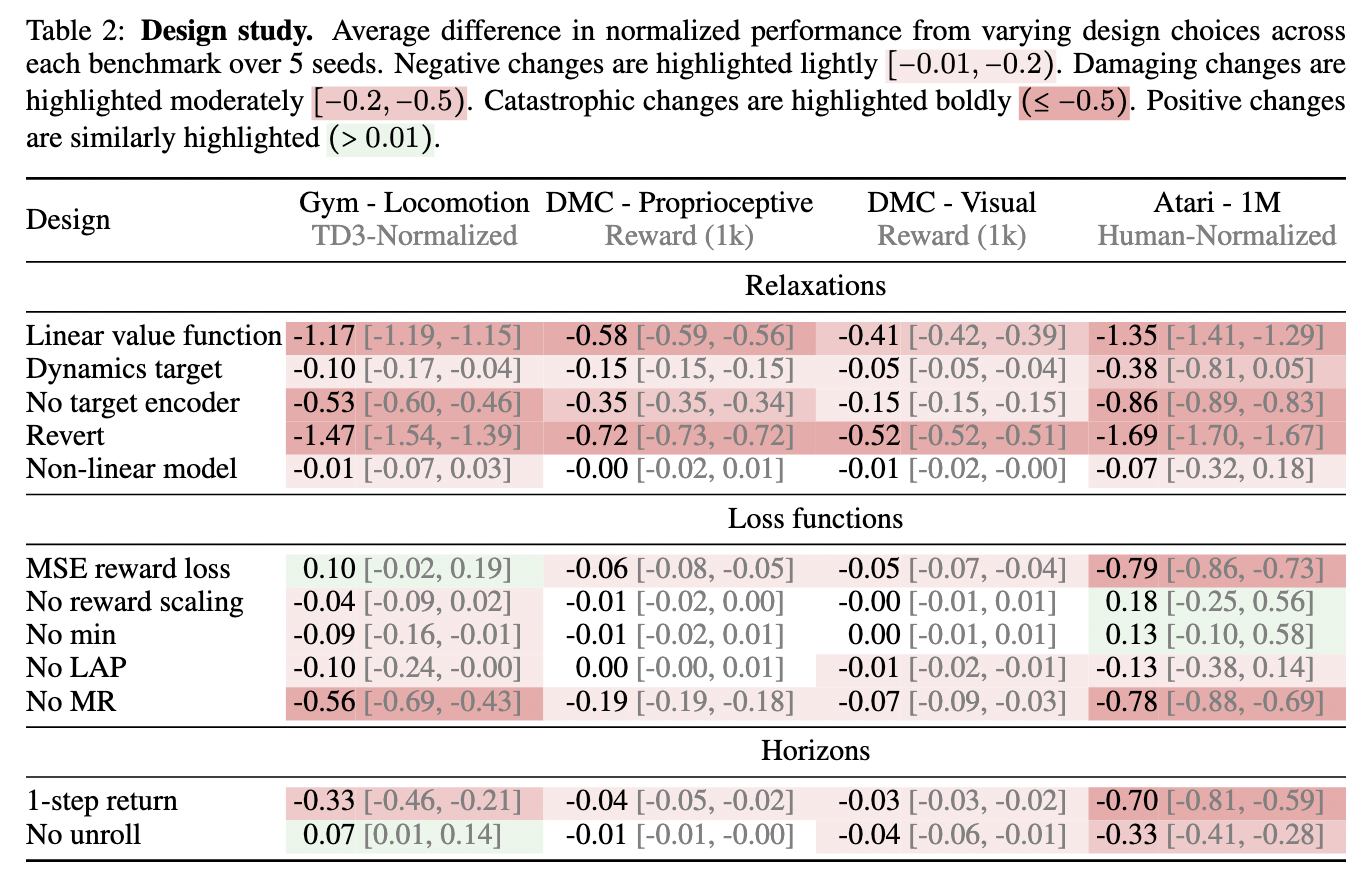
The MR.Q Framework assigns state motion pairs in embedded that keep a roughly linear relationship with the worth operate. These inlays are then processed by a non -linear operate to retain consistency in several environments. The system integrates a encoder that extracts related traits from state and motion inputs, bettering the soundness of studying. As well as, MR.Q makes use of a prioritized sampling approach and a rewards mechanism to enhance coaching effectivity. The algorithm achieves sturdy efficiency at a number of RL reference factors whereas sustaining computational effectivity by specializing in an optimized studying technique.
The experiments carried out in 4 RL reference factors (Locomotion duties of the Fitness center, Deepmind and Atari management suite) present that MR.Q achieves stable outcomes with a single set of hyperpartment. The algorithm exceeds the baselines with out standard fashions similar to PPO and DQN whereas sustaining a efficiency akin to Dreamerv3 and TD-MPC2. The MR.Q achieves aggressive outcomes whereas utilizing considerably much less computational assets, so it’s a sensible alternative for actual world purposes. At Atari’s reference level, MR.Q works significantly properly in discreet motion areas, exceeding current strategies. The MR.Q demonstrates a powerful efficiency in steady management environments, exceeding baselines with out fashions similar to PPO and DQN, whereas sustaining aggressive outcomes in comparison with Dreamerv3 and TD-MPC2. The algorithm achieves important effectivity enhancements on the reference factors with out requiring in depth reconfiguration for various duties. The analysis additional highlights MR.Q’s means to generalize successfully with out requiring in depth reconfiguration for brand new duties.
The examine underlines the advantages of incorporating representations primarily based on fashions in RL algorithms and not using a mannequin. The MR.Q marks a step to develop a really versatile body of bettering effectivity and adaptableness. Future advances might refine their strategy to handle challenges similar to exhausting exploration issues and non -Markovian environments. The outcomes contribute to the broadest goal of constructing RL methods extra accessible and efficient for a lot of purposes, positioning SR.Q as a promising software for researchers and professionals on the lookout for sturdy RL options.
Confirm he Paper. All credit score for this investigation goes to the researchers of this challenge. In addition to, do not forget to observe us Twitter and be part of our Telegram channel and LINKEDIN GRsplash. Don’t forget to hitch our 70k+ ml of submen.
🚨 Know Intellagent: A framework of a number of open supply brokers to guage a posh conversational system (Promoted)
Nikhil is an inner advisor at Marktechpost. He’s on the lookout for a double diploma built-in into supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times investigating purposes in fields similar to biomaterials and biomedical sciences. With a stable expertise in materials science, it’s exploring new advances and creating alternatives to contribute.