
 for picture classification")
{kind=link}
Introduction
Within the discipline in fast evolution of synthetic intelligence, the flexibility to interpret and analyze with precision visible information is changing into an increasing number of essential. From autonomous automobiles to medical photographs, the purposes of picture classification are huge and stunning. Nonetheless, because the complexity of duties grows, so does the necessity for fashions that may combine a number of modalities, similar to imaginative and prescient and language, to realize a extra sturdy and nuanced understanding.
That is the place imaginative and prescient language fashions (VLMS) come into play, providing a robust strategy to multimodal studying combining picture and textual content photographs to generate vital outputs. However with so many fashions accessible, how will we decide which one works finest for a selected activity? That is the issue that our purpose is to handle on this weblog.
The principle goal of this weblog is to check the superior imaginative and prescient language fashions in a activity of classification of photographs utilizing a fundamental information set and evaluate its efficiency with our basic picture recognition mannequin. As well as, we’ll show learn how to use the benchmark mannequin instrument to judge these fashions, offering details about their strengths and weaknesses. In doing so, we hope to make clear the present state of VLMS and information professionals to pick probably the most acceptable mannequin for his or her particular wants.
What are imaginative and prescient language fashions (VLMS)?
A imaginative and prescient language mannequin (VLM) is a kind of multimodal generative mannequin that may course of picture and textual content inputs to generate textual content outputs. These fashions are extremely versatile and will be utilized to quite a lot of duties, together with, amongst others ::
- Reply of Visible Doc Questions (QA): Answering questions based mostly on visible paperwork.
- Picture subtitulation: Descriptive textual content era for photographs.
- Picture classification: identification and categorization of objects inside the photographs.
- Detection: Location of objects inside a picture.
The structure of a typical VLM consists of two major parts:
- Picture traits extractor: That is normally a beforehand educated imaginative and prescient mannequin such because the Imaginative and prescient Transformer (VIT) or the clip, which extracts traits of the enter picture.
- Textual content decoder: That is usually a big language mannequin (LLM) as name or qwen, which generates textual content based mostly on the traits of the picture extracted
These two parts merge collectively utilizing a modality fusion layer earlier than being fed within the language decoder, which produces the ultimate textual content output.
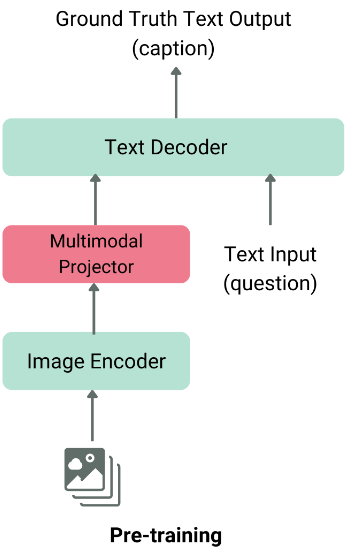
Normal structure of VLM, picture taken from the Weblog HF.
There are lots of imaginative and prescient language fashions accessible on the Clarifai platform, together with GPT-4O, Claude 3.5 Sonnet, Florence-2, Gemini, QWen2-VL-7B, Llava and MiniCPM-V. Attempt them right here!
Present standing of VLMS
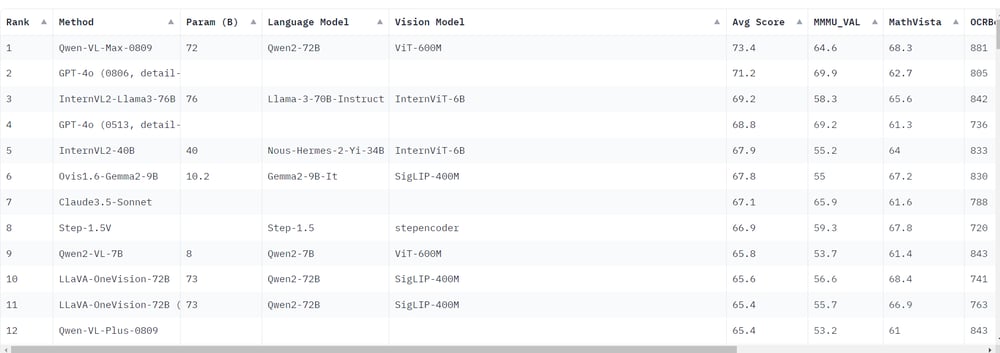
Latest classifications point out that Qwen-VL-Max-0809 has overcome GPT-4O By way of common reference scores. That is vital as a result of GPT-4O was beforehand thought-about the higher multimodal mannequin. The emergence of huge open supply fashions as QWen2-VL-7B It means that open supply fashions are starting to beat their closed code counterparts, together with GPT-4O. Specifically, QWEN2-VL-7B, regardless of its smallest dimension, achieves outcomes near these of business fashions.
Experiment configuration
{Hardware}
The experiments had been carried out within the Lambda Labs {hardware} with the next specs:
|
UPC |
RAM (GB) |
GPU |
VRM (GB) |
|---|---|---|---|
|
AMD EPYC 7J13 64 core processor |
216 |
A100 |
40 |
Curiosity fashions
We concentrate on smaller fashions (lower than 20B parameters) and embrace GPT-4O as a reference. The evaluated fashions embrace:
|
mannequin |
Mmmu |
|---|---|
|
Qwen/qwen2-vl-7b-instal |
54.1 |
|
OpenBMB/Minicpm-V-2_6 |
49.8 |
|
Meta-llama/llama-3.2-11b-vision-instruct |
50.7 (cradle) |
|
Llava-HF/Llava-V1.6-Mistral-7b-HF |
33.4 |
|
Microsoft/Phi-3-Imaginative and prescient-128k-Instruct |
40.4 |
|
llava-hf/lla3-llava-next-8b-hf |
41.7 |
|
OPENGVLAB/INTERNVL2-2B |
36.3 |
|
GPT4O |
69.9 |
Inference methods
We use two major inference methods:
- Closed set technique: We use normal metrics to check these frames, together with:
- He The mannequin is supplied with a listing of sophistication names within the message.
- To keep away from positional bias, the mannequin is requested the identical query a number of instances with the names of shuffled courses.
- The ultimate response is set by probably the most frequent class in mannequin responses.
- Instance Indicator:
“Query: Reply this query in a phrase: What sort of object is on this picture? Select one among {class1, class_n}. Reply:
“
- Binarium -based questions:
- He The mannequin is requested a sequence of questions of themselves for every class (excluding the background class).
- The method stops after the primary reply ‘Sure’, with a most of (variety of courses – 1) questions.
- Instance Indicator:
“Reply the query in a phrase: sure or no. Is the {class} on this picture?“
Outcomes
Knowledge set: Caltech256
The CALTECH256 information set consists of 30,607 photographs in 256 courses, plus a sort of background dysfunction. Every class comprises between 80 and 827 photographs, with picture sizes starting from 80 to 800 pixels. A subset of 21 courses (together with the background) for analysis was randomly chosen.
|
mannequin |
MACRO AVG |
Weighted Avg |
accuracy |
GPU (GB) (Lot Inference) |
Velocity (it/s) |
|---|---|---|---|---|---|
|
GPT4 |
0.93 |
0.93 |
0.94 |
N / A |
2 |
|
Qwen/qwen2-vl-7b-instal |
0.92 |
0.92 |
0.93 |
29 |
3.5 |
|
OpenBMB/Minicpm-V-2_6 |
0.90 |
0.89 |
0.91 |
29 |
2.9 |
|
Llava-HF/Llava-V1.6-Mistral-7b-HF |
0.90 |
0.89 |
0.90 |
|
|
|
llava-hf/lla3-llava-next-8b-hf |
0.89 |
0.88 |
0.90 |
|
|
|
Meta-Llama/Llama3.2-11b-Imaginative and prescient-Instruct |
0.84 |
0.80 |
0.83 |
33 |
1.2 |
|
OPENGVLAB/INTERNVL2-2B |
0.81 |
0.78 |
0.80 |
27 |
1.47 |
|
OpenBMB/Minicpm-V-2_6_bin |
0.75 |
0.77 |
0.78 |
|
|
|
Microsoft/Phi-3-Imaginative and prescient-128k-Instruct |
0.81 |
0.75 |
0.76 |
29 |
1 |
|
Qwen/qwen2-vl-7b-instruct_bin |
0.73 |
0.74 |
0.75 |
|
|
|
Llava-HF/Llava-V1.6-Mistral-7b-HF_bin |
0.67 |
0.71 |
0.72 |
|
|
|
Meta-Llama/Llama3.2-11b-Imaginative and prescient-Instruct_bin |
0.72 |
0.70 |
0.71 |
|
|
|
Normal picture recognition |
0.73 |
0.70 |
0.70 |
N / A |
57.47 |
|
Opengvlab/Internvl2-2b_bin |
0.70 |
0.63 |
0.65 |
|
|
|
llava-f/lla3-llava-next-8b-hf_bin |
0.58 |
0.62 |
0.63 |
|
|
|
Microsoft/Phi-3-Imaginative and prescient-128k-Instruct_bin |
0.27 |
0.22 |
0.21 |
|
|
Key observations:
Affect of the courses quantity on the closed advanced technique
We additionally examine how the variety of courses impacts the efficiency of the closed advanced technique. The outcomes are as follows:
|
Mannequin | Variety of courses |
10 |
25 |
50 |
75 |
100 |
150 |
200 |
|---|---|---|---|---|---|---|---|
|
Qwen/qwen2-vl-7b-instal |
0.874 |
0.921 |
0.918 |
0.936 |
0.928 |
0.931 |
0.917 |
|
Meta-llama/llama-3.2-11b-vision-instruct |
0.713 |
0.875 |
0.917 |
0.924 |
0.912 |
0.737 |
0.222 |
Key observations:
- The efficiency of each fashions usually improves because the variety of courses will increase as much as 100.
- Past the 100 courses, the efficiency begins to lower, with a extra vital fall noticed in meta-llama/llama-3.2-11b-vision-instructor.
Conclusion
GPT-4O remains to be a robust contender within the visual field language fashions, however open supply fashions similar to QWEN2-VL-7B are closing the hole. Our basic picture recognition mannequin, though quick, is left behind in efficiency, highlighting the necessity for higher optimization or adoption of newer architectures. The influence of the variety of courses on mannequin efficiency additionally underlines the significance of rigorously choosing the suitable mannequin for duties involving giant class units.