

{kind=link}
Impressed by the mind, neural networks They’re important for recognizing photographs and processing language. These networks depend upon activation capabilities that permit them to be taught complicated patterns. Nevertheless, many activation capabilities face challenges. Some battle with vanishing gradientswhich slows down studying in deep networks, whereas others undergo”lifeless neurons”, the place sure elements of the community cease studying. Trendy options purpose to unravel these issues, however usually undergo from drawbacks akin to inefficiency or inconsistent efficiency.
In the meanwhile, activation capabilities in neural networks face necessary issues. Options like handed and sigmoid battle with vanishing gradients, which limits their effectiveness in deep networks, and whereas tanh improved this barely, which turned out to produce other issues. ReLU addresses some gradient issues however introduces the “dying ReLU”drawback, inactivating the neurons. Variants like Leaky ReLU and PRELU They attempt to clear up them, however they create with them inconsistencies and challenges in regularization. Superior options like ELU, SiLUand GELU enhance nonlinearities. Nevertheless, it provides complexity and biases, whereas newer designs like Mish and Smish confirmed stability solely in particular circumstances and didn’t work on the whole circumstances.
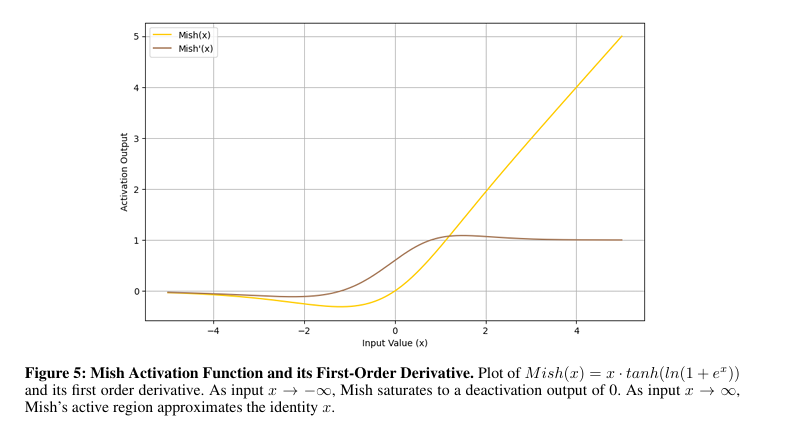
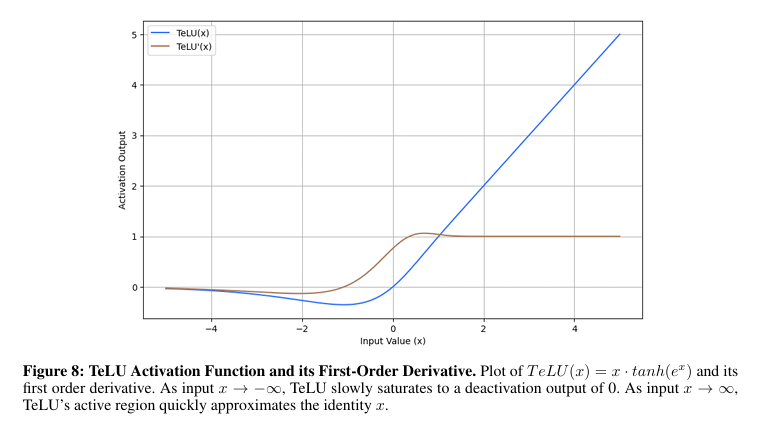
To unravel these issues, researchers from College of South Florida proposed a brand new activation perform, TeLU(x) = x · tanh(ex)that mixes the educational effectivity of ReLU with the soundness and generalization capabilities of fluid capabilities. This perform introduces clean transitions, which means that the output of the perform adjustments steadily because the enter adjustments, near-zero imply activations, and sturdy gradient dynamics to beat a few of the issues of present activation capabilities. The design goals to offer constant efficiency throughout varied duties, enhance convergence, and enhance stability with higher generalization on shallow and deep architectures.
The researchers centered on enhancing neural networks whereas sustaining computational effectivity. The researchers got down to converge the algorithm shortly, maintain it secure throughout coaching, and make it sturdy to generalization to unseen information. The perform exists in a non-polynomial and analytical method; subsequently, it could actually approximate any steady goal perform. The strategy emphasised enhancing studying stability and self-regulation whereas minimizing numerical instability. By combining linear and nonlinear properties, the framework can assist environment friendly studying and assist keep away from issues akin to gradient explosion.

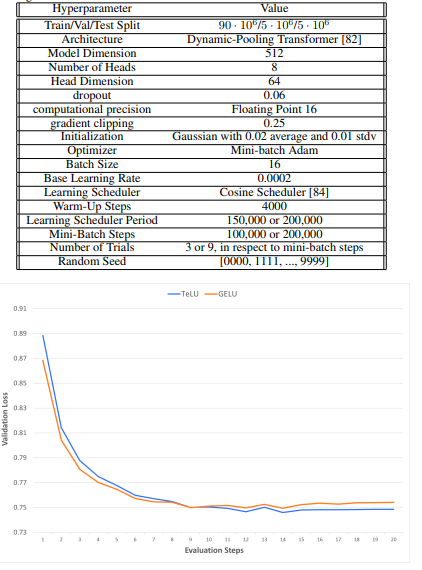
Researchers evaluated TeLU’s efficiency by way of experiments and in contrast it with different activation capabilities. The outcomes confirmed that TeLU It helped forestall the vanishing gradient drawback, which is necessary for successfully coaching deep networks. It was examined on massive information units like ImagenNet and Dynamic Grouping Transformers in Text8displaying quicker convergence and better accuracy than conventional capabilities akin to ReLU. The experiments additionally confirmed that TeLU It’s computationally environment friendly and works effectively with ReLU-based setups, usually main to higher outcomes. The experiments confirmed that TeLU It’s secure and works greatest on varied neural community architectures and coaching strategies.

In the long run, the activation perform proposed by the researchers solved the important thing challenges of present activation capabilities by stopping the vanishing gradient drawback, enhancing computational effectivity, and displaying higher efficiency on varied information units and architectures. Its profitable utility on benchmarks akin to ImageNet, Text8, and Penn Treebank, displaying quicker convergence, accuracy enhancements, and stability in deep studying fashions, might place TeLU as a promising instrument for deep neural networks. Moreover, the efficiency of TeLU can function a basis for future analysis, which might encourage additional improvement of activation capabilities to attain even higher effectivity and reliability in machine studying developments.
Confirm he Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, remember to observe us on Twitter and be part of our Telegram channel and LinkedIn Grabove. Remember to hitch our SubReddit over 60,000 ml.
🚨 UPCOMING FREE AI WEBINAR (JANUARY 15, 2025): Improve LLM Accuracy with Artificial Information and Evaluation Intelligence–Be a part of this webinar to be taught sensible info to enhance LLM mannequin efficiency and accuracy whereas defending information privateness..
Divyesh is a Consulting Intern at Marktechpost. He’s pursuing a BTech in Agricultural and Meals Engineering from the Indian Institute of Know-how Kharagpur. He’s an information science and machine studying fanatic who needs to combine these main applied sciences in agriculture and clear up challenges.