

{kind=link}
Pure Storage at present introduced Flashblade // Exa, a brand new flash storage matrix designed to satisfy the demanding wants of AI factories and the coaching of multimodal AI. Flashblade // EXA separates the layer of metadata from the info route within the I/O sequence, which Pure says that the matrix strikes the info charges larger than 10 terabytes per second by house.
Flashblade // exa is an growth of Pure storagePresent provides, together with Flashblade // S, its excessive efficiency matrix for file and object workloads, in addition to Flashblade // E, its massive -scale matrix designed to retailer unstructured information.
The brand new matrix divides excessive -speed I/Os into two components. The metadata are cracked via the central part of flashblade // exa metadata, which is predicated on nodes of the Directflash Directflash excessive pace module that home the corporate’s key -scale worth retailer of the corporate. Metadata core nodes are executed within the purity working system // FB, which has been strengthened with assist for parallel NFS (PNF) to speak with laptop nodes.
Block information is traluted individually via distant entry to direct reminiscence (RDMA) to information nodes, that are commonplace commonplace servers based mostly on commonplace LINUX with this model (the corporate plans to include its DFM expertise in a future model). This structure permits Flashblade // exa to achieve the utmost bandwidth allowed between information storage and laptop nodes.
“This segregation supplies information entry with out blocking that will increase exponentially in excessive efficiency laptop eventualities the place metadata requests can match, if they don’t exceed the info quantity, information I/O operations,” writes Alex Castro, a pure storage vice chairman, In a weblog put up.

Flashblade // EXA separates the sequence of metadata from the block information sequence, eliminating an I/O bottleneck, says Pure Storage
When Solar Microsystems created NFS in 1984, the performance was the principle strategy, not the efficiency, says Castro. Nonetheless, inherited NAS units that require extra I/O controllers with every new information node have created a bottleneck for efficiency. Divar the I/O is the important thing to unlocking the bottleneck created by Legacy Nas Arrays, he says.
“Many storage suppliers aimed on the excessive efficiency nature of the good workloads of AI solely resolve half of the parallelism downside, providing the best attainable community bandwidth in order that prospects attain the info goals,” writes Castro. “They don’t deal with how metadata and information to mass efficiency are attended, which is the place massive -scale bottlenecks come up.”
Some storage suppliers have resorted to the usage of particular file techniques, reminiscent of Luster, to supply the parallelism obligatory for giant -scale initiatives, Castro writes, however these environments had been liable to the latency of metadata and required doctoral stage abilities to manage. However, different suppliers have inserted a calculation aggregation layer between laptop prospects and the info supply.
“This mannequin suffers from growth stiffness and extra administration complexity challenges than PNF by climbing for mass efficiency as a result of it implies including extra transferring components with calculation aggregation nodes,” says Castro. “This rigidity forces the info and metadata to climb in Lockstep, creating inefficiencies for multimodal and dynamic workloads.”
Supply: pure storage
Pure says that he developed the flashblade // exa to satisfy the rising wants of “AI factories”, and particularly the necessity to preserve 1000’s of excessive -end GPU fueled with information.
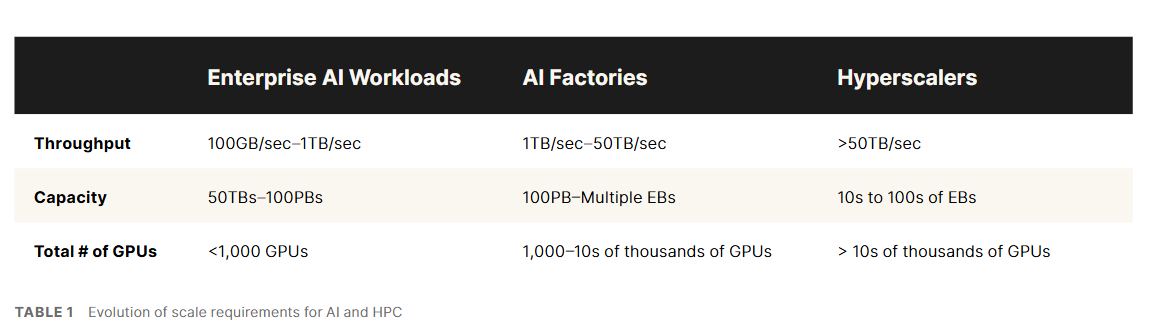
When it comes to scale, AI factories sit within the center. On the decrease finish are the enterprise workloads of AI, reminiscent of inference and rag, which function at 50TB at 100pb of knowledge, whereas AI factories will want entry to as much as 10,000 GPU in 100pb information units to a number of exabytes. On the higher finish, hyperscalers can have greater than 100 ° and greater than 10,000 GPU. In any respect ranges, having inactive GPU is an obstacle to productiveness.
“The information is the gasoline for AI enterprise factories, immediately impacting the efficiency and reliability of AI purposes,” stated Rob Davis, vice chairman of NVIDIA storage community expertise. “With NVIDIA networks, the Flashblade // EXA platform permits organizations to benefit from the potential of AI applied sciences whereas sustaining information safety, scalability and efficiency for the coaching of fashions, fantastic adjustment and the newest inference necessities for AI and reasoning of the AI.”
Pure Storage says he hopes to start out sending Flashblade // exa this summer season.
Associated articles:
Ai to the demand for goose for all flash matrices, says Pure Storage
Why the storage of objects is the response to the best problem of AI
PURE STORAGE ROLLS ALL-QLC FLASH ARRAY