

{kind=link}
Over the previous six months, Rockset’s engineering crew has totally built-in similarity indexes into its search and evaluation database.
Indexing has at all times been on the forefront of Rockset know-how. Rockset created a converged index that features parts of a search index, a column retailer, a row retailer, and now a similarity index that may scale to billions of vectors and terabytes of knowledge. We now have designed these indexes to assist real-time updates in order that streaming knowledge may be obtainable for search in lower than 200 milliseconds.
Earlier this 12 months, Rockset launched a brand new cloud structure with separation between compute and compute storage. Because of this, the newly added vector and metadata indexing doesn’t negatively affect search efficiency. Customers can repeatedly stream and index vectors fully remoted from search. This structure is advantageous for knowledge transmission and in addition for similarity indexing, as these are resource-intensive operations.
What we have now additionally seen is that vector search will not be by itself island. Many purposes apply filters to vector search utilizing textual content, geographic knowledge, time collection, and extra. Rockset makes hybrid search as straightforward as an SQL WHERE clause. Rockset has harnessed the facility of the search index with a built-in SQL engine so your queries at all times run effectively.
On this weblog, we’ll delve into how Rockset has totally built-in vector search in your search and evaluation database. We’ll describe how Rockset has designed its resolution for native SQL, real-time updates, and compute separation.
Watch the technical speak at How we create vector search within the cloud with chief architect Tudor Bosman and engineer Daniel Latta-Lin. Hear how they created a distributed similarity index utilizing FAISS-IVF that saves reminiscence and helps rapid insertion and retrieval.
FAISS-IVF on Rockset
Whereas Rockset is algorithm-agnostic in its implementation of similarity indexing, for the preliminary implementation we leverage FAISS-IVF as it’s broadly used, properly documented and helps updates.
There are a number of strategies to index vectors together with constructing a graph, a tree knowledge construction, and an inverted file construction. Tree and graph constructions take longer to construct, making them computationally costly and time-consuming to assist use circumstances with continuously up to date vectors. The inverted file methodology is very appreciated as a consequence of its quick indexing time and search efficiency.
Whereas the FAISS Library is open supply and may be leveraged as a standalone index, customers want a database to handle and scale vector search. That is the place Rockset is available in as a result of it has solved database challenges, together with question optimization, multi-tenancy, sharding, consistency, and extra that customers want when scaling vector search purposes.
Implementation of FAISS-IVF in Rockset
As a result of Rockset is designed to scale, it creates a distributed FAISS similarity index that saves reminiscence and helps rapid insertion and retrieval.
Utilizing a DDL commandA consumer creates a similarity index on any vector subject in a Rockset assortment. Beneath the hood, the inverted file indexing algorithm splits the vector area into Voronoi cells and assigns every partition a centroid, or the purpose that falls on the heart of the partition. The vectors are then assigned to a partition or cell, primarily based on the centroid they’re closest to.
CREATE SIMILARITY INDEX vg_ann_index
ON FIELD confluent_webinar.video_game_embeddings:embedding
DIMENSION 1536 as 'faiss::IVF256,Flat';
An instance of the DDL command used to create a similarity index in Rockset.
On the time of similarity index creation, Rockset creates a publishing record of centroids and their identifiers that’s saved in reminiscence. Every document within the assortment can be listed and extra fields are added to every document to retailer the closest centroid and the residual, offset, or distance from the closest centroid. The gathering is saved on SSD for improved efficiency and cloud object storage for sturdiness, providing higher worth and efficiency than in-memory vector database options. As new information are added, their closest centroids and residuals are calculated and saved.
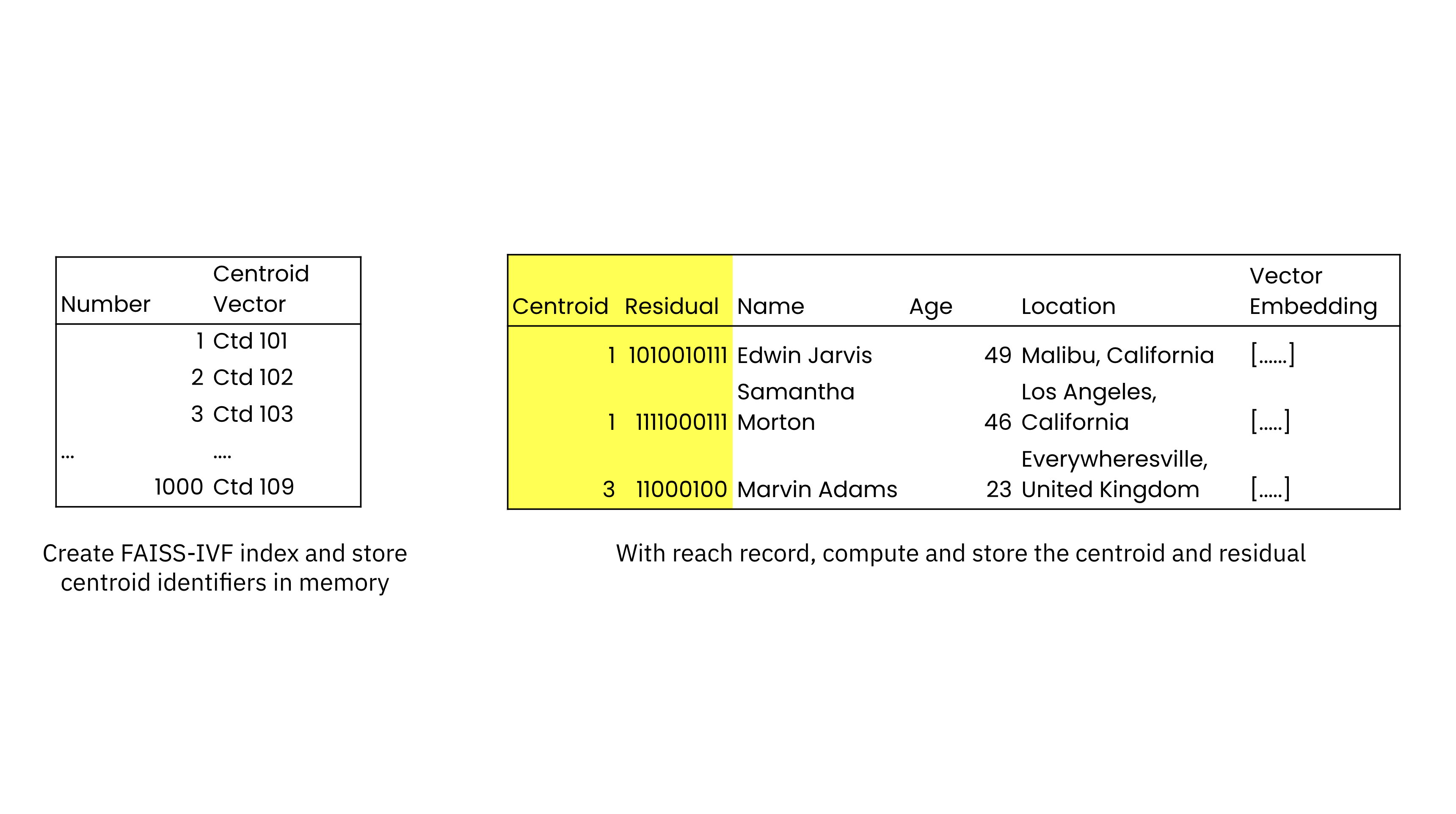
With Rockset Convergent indexvector search can benefit from each similarity index and parallel search. When operating a search, the Rockset question optimizer obtains the centroids closest to the goal FAISS embedding. Rockset’s question optimizer then searches the centroids utilizing the search index to return the consequence.

Rockset additionally provides the consumer flexibility to commerce off between restoration and pace for his or her AI software. On the time of making the similarity index, the consumer can decide the variety of centroidswith extra centroids, which results in quicker search but in addition longer indexing time. On the time of the question, the consumer may also choose the variety of probes or the variety of cells to look, balancing between pace and precision of the search.
Rockset’s implementation minimizes the quantity of knowledge saved in reminiscence, limiting it to an inventory of posts, and leverages the similarity index and search index to enhance efficiency.
Create purposes with real-time updates
one of many well-known tough challenges Insertions, updates and deletions are dealt with with vector search. It’s because vector indices are fastidiously organized for quick searches and any try to replace them with new vectors will shortly deteriorate the quick search properties.
Rockset helps streaming vector and metadata updates effectively. Rockset is predicated on RocksDBan open supply embedded storage engine designed for mutability and constructed by the crew behind Rockset at Meta.
Utilizing RocksDB internally permits Rockset to assist field-level mutations, so an replace to the vector on a person document will set off a question to FAISS to generate the brand new centroid and residual. Rockset will then replace solely the centroid and residual values for an up to date vector subject. This ensures that new or up to date vectors may be queried in roughly 200 milliseconds.

Separation of indexing and search.
rockset calculation-computation separation ensures that steady streaming and vector indexing is not going to have an effect on search efficiency. Within the Rockset structure, one digital occasion, a gaggle of compute nodes, can be utilized to ingest and index knowledge, whereas different digital situations can be utilized to carry out queries. A number of digital situations can concurrently entry the identical knowledge set, eliminating the necessity for a number of knowledge replicas.
The separation of computing makes it attainable for Rockset to assist simultaneous indexing and looking. In many different vector databasesYou can not carry out reads and writes in parallel, so you might be compelled to batch load knowledge exterior of enterprise hours to make sure constant search efficiency of your software.
Separating calculations additionally ensures that when similarity indices have to be periodically retrained to maintain recall excessive, there is no such thing as a interference with search efficiency. It’s well-known that periodically retraining the index may be computationally costly. In lots of programs, together with elastic searchreindex and search operations happen on the identical cluster. This introduces the opportunity of indexing negatively interfering with the applying’s search efficiency.
By separating compute, Rockset avoids the issue of indexing impacting search to realize predictable efficiency at any scale.

Hybrid search as straightforward as an SQL WHERE clause
Many vector databases Offers restricted assist for hybrid search or metadata filtering and restricts subject varieties, metadata updates, and metadata measurement. Constructed for search and analytics, Rockset treats metadata like first-class residents and helps paperwork as much as 40MB in measurement.
The explanation many new vector databases restrict metadata is that filtering knowledge extremely quick is a really tough downside. If you happen to had been requested the query: “Give me 5 nearest neighbors the place
As a consumer, you’ll be able to inform Rockset that you’re open to a fuzzy nearest neighbor search and commerce off some precision for pace within the search question utilizing approx_dot_product both approx_euclidean_dist.
WITH dune_embedding AS (
SELECT embedding
FROM commons.book_catalogue_embeddings catalogue
WHERE title="Dune"
LIMIT 1
)
SELECT title, writer, score, num_ratings, worth,
APPROX_DOT_PRODUCT(dune_embedding.embedding, book_catalogue_embeddings.embedding) similarity,
description, language, book_format, page_count, liked_percent
FROM commons.book_catalogue_embeddings CROSS JOIN dune_embedding
WHERE score IS NOT NULL
AND book_catalogue_embeddings.embedding IS NOT NULL
AND writer != 'Frank Herbert'
AND score > 4.0
ORDER BY similarity DESC
LIMIT 30
a session with approx_dot_product which is a tough measure of how intently two vectors align.
Rockset makes use of the search index to filter by metadata and prohibit the search to the closest centroids. This system is named single-stage filtering and is in distinction to two-pass filtering, together with pre- and post-filtering, which may induce latency.
Cloud Scale Vector Search
At Rockset, we have spent years constructing a search and analytics database at scale. It has been designed from the bottom up for the cloud with useful resource isolation which is essential when constructing real-time purposes or purposes that run 24/7. In buyer workloads, Rockset has scaled to 20,000 QPS sustaining a P50 knowledge latency of 10 milliseconds.
Because of this, we see firms already utilizing vector seek for manufacturing purposes at scale. JetBlueknowledge chief within the airline trade, makes use of Rockset as its vector search database to make operational choices about flights, crew and passengers utilizing LLM-based chatbots. Somethingthe quickest rising market within the US, makes use of Rockset to energy AI suggestions on its dwell public sale platform.
In case you are constructing an AI software, we invite you to begin one free trial from Rockset or study extra about our know-how to your use case in a product demonstration.
Watch the technical speak at How we create vector search within the cloud with chief architect Tudor Bosman and engineer Daniel Latta-Lin. Hear how they created a distributed similarity index utilizing FAISS-IVF that saves reminiscence and helps rapid insertion and retrieval.