

{kind=link}
The mathematical fashions of huge language (LLM) have demonstrated robust downside fixing capabilities, however their reasoning capability is usually restricted by the popularity of patterns as an alternative of true conceptual understanding. Present fashions are largely primarily based on publicity to related assessments as a part of their coaching, limiting their extrapolation to new mathematical issues. This restriction restricts the LLM of taking part in superior mathematical reasoning, particularly in issues that require differentiation between intently associated mathematical ideas. A complicated reasoning technique that generally lacks LLM is the check by counterexample, a central technique to refute false mathematical statements. The absence of enough era and use of counterexamples makes it troublesome for LLMs within the conceptual reasoning of superior arithmetic, which decreases their reliability within the formal verification of the concept and mathematical exploration.
The earlier makes an attempt to enhance mathematical reasoning in LLM have labeled into two basic approaches. The primary strategy, the era of artificial issues, Trains LLMS in huge knowledge units generated from seed arithmetic issues. For instance, Wizardmath USA GPT-3.5 to generate issues of various ranges of issue. The second strategy, the formal verification theorem, permits fashions to work with check programs corresponding to Lean 4, as within the Draft-Sketch-Show and Lean-Star, which assist LLM within the structured theorem check. Though these approaches have improved downside fixing capability, they’ve extreme limitations. The era of artificial questions generates memorization and never a real understanding, leaving susceptible fashions to failure in opposition to new issues. Formal improvisation methods of the concept, then again, are restricted by being primarily based on structured mathematical languages that restrict their utility to a number of mathematical contexts. These limitations underline the necessity for another paradigm, an paradigm that refers to conceptual understanding as an alternative of patterns recognition.
To deal with these limitations, a mathematical reasoning level is launched pushed by a counterexample, often known as the counter -ram. The reference level is constructed particularly to guage and enhance the usage of LLMS counterexamples in check. Improvements cowl a top quality reference level, an information engineering course of and evaluations of exhaustive fashions. The countermelted consists of 1,216 mathematical statements, every of which wants a counterexample to refute. The issues are cured by the hand of college textbooks and extensively validated by specialists. To enhance the reasoning primarily based on the counter -example of LLM, an automatic knowledge assortment course of is applied, filtering and refining mathematical check knowledge to acquire examples of reasoning primarily based on counterexamples. The efficacy of the newest era arithmetic, corresponding to OPENAI’s O1 mannequin and tune in tuned open supply variants, is rigorously examined within the countermelter. When diverting the strategy to reasoning primarily based on instance of the unique provision of the concept, this technique initiates a novel and little explored route to coach the mathematical LLMs.

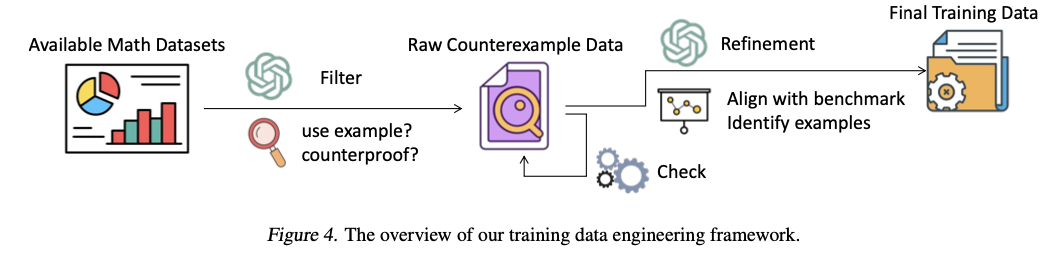
The counter -ram is constructed primarily based on 4 central mathematical disciplines: algebra, topology, actual evaluation and purposeful evaluation. The info is in-built a a number of steps course of. First, mathematical statements are collected from textbooks and convert to structured knowledge via OCR. Mathematicians then evaluation and write down every downside to acquire logical consistency and precision. Skilled translations are made as unique knowledge in Chinese language, adopted by extra controls. There’s additionally an information engineering framework within the job to robotically recuperate coaching knowledge for a reasoning primarily based on counterexample. GPT-4O filtering and refinement methods are utilized on this body Reasoning primarily based on a extra successfully counterexample.
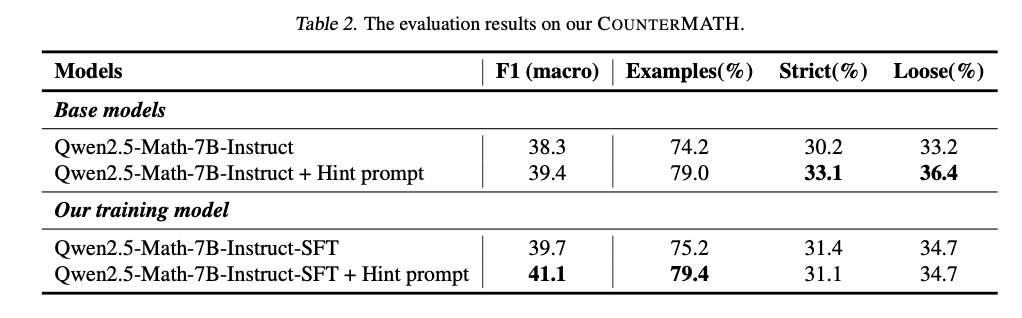
The analysis of the avant -garde mathematician LLM within the countermelter reveals important gaps within the reasoning pushed by counterexample. Most fashions don’t choose whether or not a press release is true or false utilizing counterexamples, which displays a deep conceptual weak point. The efficiency can also be blended in all mathematical areas, with algebra and purposeful evaluation that works greatest, and the topology and actual evaluation stay very difficult as a consequence of their summary nature. Open supply fashions work worse than patented fashions, and only some have average conceptual reasoning. Nonetheless, adjustment with knowledge primarily based on a counterexample considerably will increase efficiency, with a greater precision of the trial and a reasoning primarily based on instance. A adjusted mannequin, with just one,025 coaching samples primarily based on a counterexample, works considerably higher than its reference variations and has a powerful generalization to the maths assessments out of distribution. An in depth analysis reported in Desk 1 under reveals efficiency comparisons primarily based on F1 scores and reasoning consistency metrics. QWEN2.5-Math-72B-INSTrust works greatest (41.8 F1) amongst open supply fashions, however is behind patented fashions corresponding to GPT-4O (59.0 F1) and OpenAI O1 (60.1 F1). The effective adjustment results in important income, with QWEN2.5-Math-7B-INSTRUCT-Sft + Intrajo de Signo Settlement 41.1 F1, affirming the effectiveness of coaching primarily based on the counterexample.

This proposed technique presents the countermelter, a reasoning level of reasoning primarily based on a counterexample designed to enhance the conceptual mathematical abilities of LLMS. The usage of properly -cured issues units and a automated knowledge refinement course of demonstrates that current LLMs should not competent in deep mathematical reasoning, however will be significantly improved with coaching primarily based on counterexamples. These outcomes indicate that the longer term analysis of AI ought to give attention to bettering conceptual understanding and never publicity -based studying. Contradicate reasoning just isn’t solely important in arithmetic, but additionally in logic, scientific analysis and formal verification, and this technique will be prolonged to all kinds of analytical duties pushed by AI.
Confirm he Paper. All credit score for this investigation goes to the researchers of this challenge. As well as, be happy to observe us Twitter And remember to affix our 75K+ ml of submen.
Aswin AK is a consulting intern in Marktechpost. He’s chasing his double title on the Indian Know-how Institute, Kharagpur. He’s keen about knowledge science and automated studying, offering a strong educational expertise and a sensible expertise in resolving actual -life dominance challenges.
