

{kind=link}
Giant language fashions (LLM) have turn out to be indispensable for a number of pure language processing functions, together with computerized translation, textual content abstract and conversational AI. Nevertheless, their rising complexity and dimension have led to important challenges of computational effectivity and reminiscence consumption. As these fashions develop, the demand for sources makes them troublesome to implement in environments with restricted computing capabilities.
The primary impediment with LLMS lies in its mass laptop necessities. The coaching and adjustment of those fashions contain billions of parameters, making them intensive in sources and limiting their accessibility. The prevailing strategies to enhance effectivity, comparable to advantageous adjustment of parameters (PEFT), present some reduction, however typically compromise efficiency. The problem is to seek out an strategy that may considerably cut back computational calls for whereas sustaining the precision and effectiveness of the mannequin in actual world eventualities. Researchers have been exploring strategies that enable environment friendly fashions adjustment with out requiring intensive computational sources.
Intel Labs and Intel Company researchers have launched an strategy that integrates low -ranking adaptation (Lora) with neuronal structure search strategies (NAS). This methodology seeks to handle the constraints of conventional advantageous adjustment approaches whereas bettering effectivity and efficiency. The analysis group developed a framework that optimizes reminiscence consumption and computational velocity by profiting from low -ranking structured representations. The method implies a brilliant community to share the burden that dynamically adjusts the substructures to enhance coaching effectivity. This integration permits the mannequin to regulate successfully whereas sustaining a minimal computational footprint.
The methodology launched by Intel Labs focuses on canvases (seek for low -ranking neuronal structure), which makes use of elastic LORA adapters for the adjustment of the mannequin. In contrast to standard approaches that require full advantageous adjustment of LLMS, canvases permits the selective activation of mannequin substructures, decreasing redundancy. Key innovation lies within the flexibility of elastic adapters, that are dynamically adjusted relying on the necessities of the mannequin. The strategy is backed by sub-Pink heuristic searches that additional expedite the adjustment course of. By focusing solely on the parameters of the related mannequin, the method achieves a stability between computational effectivity and efficiency. The method is structured to permit selective activation of low -rank buildings whereas sustaining a excessive inference velocity.
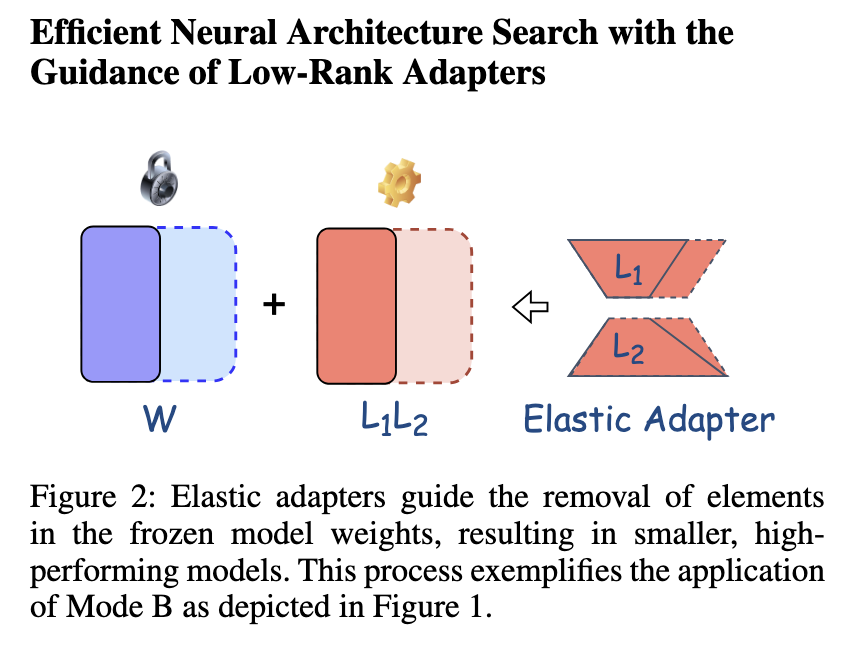
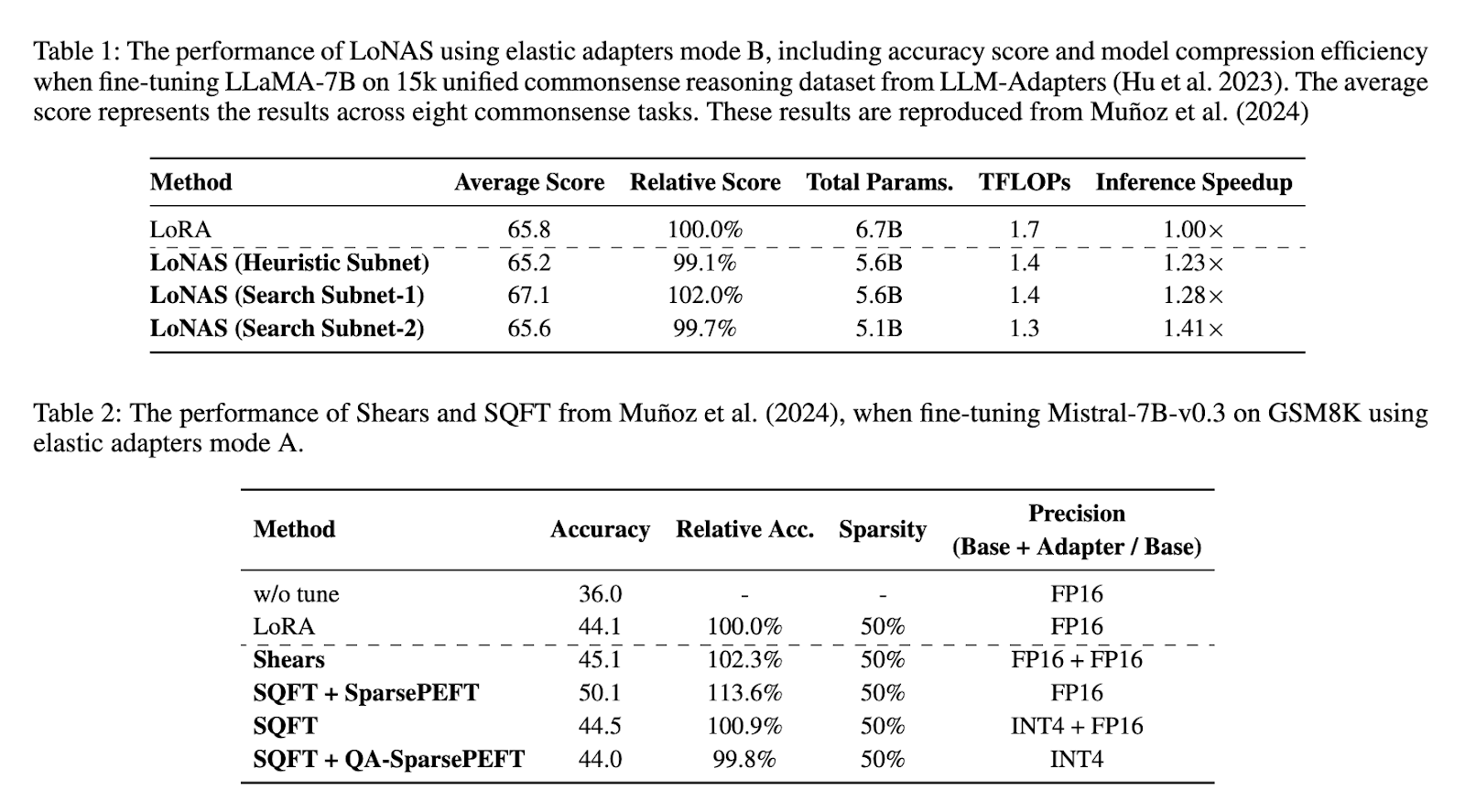
The efficiency analysis of the proposed methodology highlights its important enhancements on standard strategies. Experimental outcomes point out that Canvas achieves an inference acceleration of as much as 1.4x whereas decreasing mannequin parameters by roughly 80%. When utilized to flame-7b of advantageous adjustment in a set of unified frequent reasoning knowledge of 15k, canvases demonstrated a mean precision rating of 65.8%. A comparative evaluation of various canvas configurations confirmed that the optimization of the heuristic subnet achieved an inference acceleration of 1.23x, whereas the configurations of the search subnet confirmed accelerations of 1.28xy 1.41x. As well as, the applying of canvases to Mistral-7B-V0.3 in GSM8K duties elevated the accuracy of 44.1% to 50.1%, sustaining effectivity within the completely different sizes of the mannequin. These findings affirm that the proposed methodology considerably improves the efficiency of the LLM whereas decreasing the computational necessities.
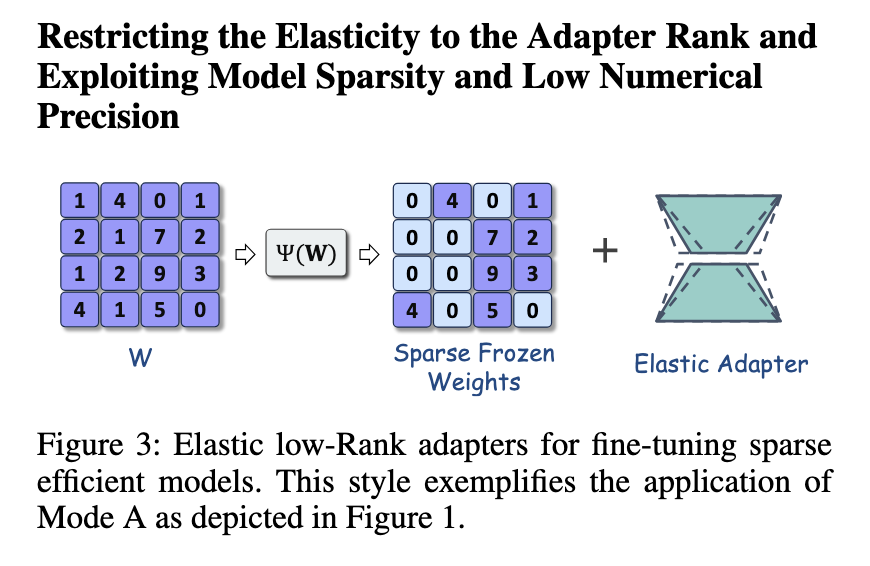
Extra enhancements to the body embrace the introduction of shear, a sophisticated advantageous adjustment technique based mostly on canvases. The shear use the seek for the low -ranking adapter (NLS) to limit elasticity to the adapter vary, decreasing pointless calculations. The strategy applies scarcity to the bottom mannequin utilizing predefined metrics, making certain that the advantageous adjustment is environment friendly. This technique has been significantly efficient in sustaining the precision of the mannequin whereas decreasing the variety of lively parameters. One other extension, SQFT, incorporates scarcity and low numerical precision for improved improved adjustment. Utilizing quantization strategies, SQFT ensures that scarce fashions will be adjusted with out shedding effectivity. These refinements spotlight the adaptability of canvases and their potential for better optimization.
The mixing of Lora and NAS affords a remodeling strategy to Giant Language Mannequin enchancment. By profiting from structured low -rank representations, analysis demonstrates that computational effectivity will be improved considerably with out compromising efficiency. The research by Intel Labs confirms that the mixture of those strategies reduces the adjustment load to the time that ensures the integrity of the mannequin. Future analysis may discover extra optimizations, together with the improved Sub-Rred and probably the most environment friendly heuristic methods. This strategy establishes a precedent to make the LLMs extra accessible and deployable in varied environments, paving the way in which for extra environment friendly fashions.
Confirm he Paper and Github web page. All credit score for this investigation goes to the researchers of this challenge. Moreover, do not forget to observe us Twitter and be part of our Telegram channel and LINKEDIN GRsplash. Don’t forget to hitch our 70k+ ml of submen.
🚨 Know Intellagent: A framework of a number of open supply brokers to guage a posh conversational system (Promoted)
Nikhil is an inner advisor at Marktechpost. He’s in search of a double diploma built-in into supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time investigating functions in fields comparable to biomaterials and biomedical sciences. With a stable expertise in materials science, it’s exploring new advances and creating alternatives to contribute.