

{kind=link}
Multimodal fashions purpose to create programs that may seamlessly combine and make the most of a number of modalities to supply a complete understanding of the info offered. Such programs purpose to copy human-like notion and cognition by processing advanced multimodal interactions. By leveraging these capabilities, multimodal fashions are paving the way in which for extra refined AI programs that may carry out varied duties, reminiscent of visible query answering, speech technology, and interactive storytelling.
Regardless of advances in multimodal fashions, present approaches nonetheless must be reviewed. Many present fashions can’t course of and output information in several modalities or focus solely on one or two sorts of enter, reminiscent of textual content and pictures. This results in restricted scope of utility and diminished efficiency when dealing with advanced real-world situations that require integration between a number of modalities. Moreover, most fashions can’t create interlaced content material (combining textual content with visible or audio components), which hinders their versatility and usefulness in sensible functions. Addressing these challenges is important to unlock the true potential of multimodal fashions and allow the event of sturdy AI programs able to understanding and interacting with the world extra comprehensively.
Present strategies in multimodal analysis sometimes depend on separate encoders and alignment modules to course of various kinds of information. For instance, fashions reminiscent of EVA-CLIP and CLAP use encoders to extract options from photos and align them with textual content representations by way of exterior modules reminiscent of Q-Former. Different approaches embrace fashions reminiscent of SEED-LLaMA and AnyGPT, which give attention to combining textual content and pictures however don’t help complete multimodal interactions. Whereas GPT-4o has made progress in supporting information inputs and outputs of any sort, it’s closed supply and lacks capabilities to generate interleaved sequences involving greater than two modalities. These limitations have led researchers to discover new coaching architectures and methodologies that may unify understanding and technology in varied codecs.
The analysis workforce from Beihang College, AIWaves, Hong Kong Polytechnic College, College of Alberta and several other famend institutes, in a collaborative effort, have launched a novel mannequin referred to as MIO (Multimodal Enter and Output), designed to surpass present fashions. limitations. MIO is an open supply multimodal core mannequin able to processing textual content, speech, photos and movies in a unified framework. The mannequin helps the technology of interlaced sequences involving a number of modalities, making it a flexible device for advanced multimodal interactions. By a complete four-stage coaching course of, MIO aligns discrete tokens throughout 4 modalities and learns to generate constant multimodal outcomes. Corporations creating this mannequin embrace MAP and AIWaves, which have contributed considerably to the development of multimodal AI analysis.

MIO’s distinctive coaching course of consists of 4 phases to optimize your multimodal understanding and technology capabilities. The primary stage, alignment pre-training, ensures that the mannequin’s non-textual information representations are aligned with its linguistic area. That is adopted by interleaved pre-training, which includes varied sorts of information, together with interleaved video-text and image-text information, to enhance the mannequin’s contextual understanding. The third stage, enhanced speech pretraining, focuses on bettering speech-related talents whereas sustaining balanced efficiency in different modalities. Lastly, the fourth stage entails supervised adjustment utilizing a wide range of multimodal duties, together with visible storytelling and visible thought chain reasoning. This rigorous coaching method permits MIO to deeply perceive multimodal information and generate interwoven content material that seamlessly combines textual content, voice, and visible data.
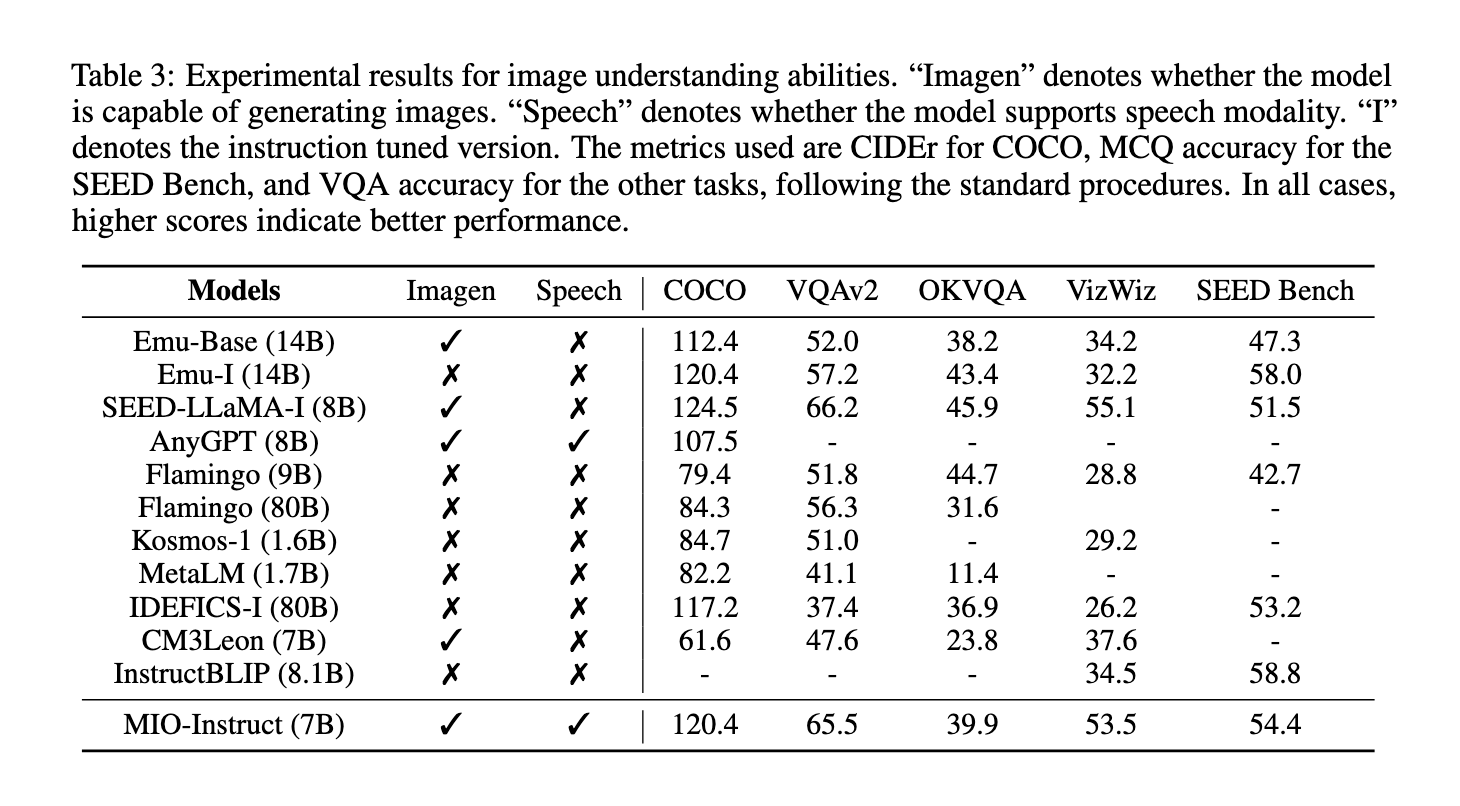
Experimental outcomes present that MIO achieves state-of-the-art efficiency on varied benchmarks, outperforming present dual- and any-any multimodal fashions. In visible query answering duties, MIO achieved an accuracy of 65.5% on VQAv2 and 39.9% on OK-VQA, outperforming different fashions reminiscent of Emu-14B and SEED-LLaMA. In speech-related assessments, MIO demonstrated superior capabilities, reaching a phrase error charge (WER) of 4.2% in computerized speech recognition (ASR) and 10.3% in text-to-speech (TTS) duties. . The mannequin additionally excelled in video comprehension duties, with a high accuracy of 42.6% on MSVDQA and 35.5% on MSRVTT-QA. These outcomes spotlight the robustness and effectivity of MIO in dealing with advanced multimodal interactions, even in comparison with bigger fashions reminiscent of IDEFICS-80B. Moreover, MIO’s efficiency in interlaced video-text technology and visible thought chain reasoning exhibits its distinctive talents to generate coherent and contextually related multimodal outcomes.

Total, MIO presents a big advance within the growth of primary multimodal fashions, offering a strong and environment friendly answer for integrating and producing content material by way of textual content, voice, photos and movies. Its complete coaching course of and superior efficiency throughout a number of benchmarks exhibit its potential to set new requirements in multimodal AI analysis. The collaboration between Beihang College, AIWaves, Hong Kong Polytechnic College and plenty of different famend institutes has resulted in a strong device that bridges the hole between multimodal understanding and technology, paving the way in which for future improvements in synthetic intelligence .
have a look at the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, remember to observe us on Twitter and be a part of our Telegram channel and LinkedIn Grabove. In case you like our work, you’ll love our data sheet..
Remember to hitch our SubReddit over 50,000ml
Wish to get in entrance of over 1 million AI readers? Work with us right here
Nikhil is an inside advisor at Marktechpost. He’s pursuing an built-in double diploma in Supplies on the Indian Institute of Expertise Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching functions in fields like biomaterials and biomedical science. With a powerful background in supplies science, he’s exploring new advances and creating alternatives to contribute.