

{kind=link}
Getting into the period with out server
On this weblog, we share the journey to construct an optimized artifact document with out server from scratch. The primary aims are to ensure the distribution of the container picture each scales with out issues underneath site visitors with out noisy server and stay accessible in difficult eventualities, such because the essential dependency failures.
Containers are the trendy cloud native implementation format that has insulation, portability and wealthy software ecosystems. Databricks inside providers have been executed as containers since 2017. We applied an open supply undertaking wealthy and wealthy in wealthy because the container document. It labored nicely, because the providers have been typically applied at a managed charge.
Let’s rapidly advance till 2021, when Databricks started to begin DBSQL with out server and product fashions, tens of millions of digital machines have been anticipated to be equipped day-after-day, and every VM would extract greater than 10 photos from the container document. Not like different inside providers, with out server picture extraction site visitors is pushed by buyer use and may attain a a lot larger higher restrict.
Determine 1 is a 1 week manufacturing site visitors load (for instance, clients who launch new information shops or remaining service factors) that reveals that most site visitors with out server is greater than 100 instances in comparison with that of inside providers.
In accordance with our stress assessments, we conclude that the registration of open supply containers couldn’t meet the necessities with out server.
Challenges with out server
Determine 2 reveals the primary challenges to serve work masses with out server with open supply container registration:
- Not dependable sufficient: OSS information typically have a posh structure and dependencies, similar to relational databases, which offer failure modes and an important radius of explosion.
- It’s tough to maintain up with the expansion of Databricks: In open supply implementation, picture metadata are backed by relational databases vertically and distant cache cases. The extension is sluggish, generally it has been greater than 10 minutes. They are often overload because of the subprovisión or too costly to execute when they’re supplied an excessive amount of.
- Costly to function: OSS information aren’t optimized by efficiency and have a tendency to have a excessive use of sources (CPU intensive). Executing them on the Databricks scale is prohibitively costly.
What in regards to the cloud -administered container information? They’re typically extra scalable and provide SLA availability. Nevertheless, the totally different cloud suppliers providers have totally different installments, limitations, reliability, scalability and efficiency traits. Databricks operates in a number of clouds, we discovered that the heterogeneity of the clouds didn’t meet the necessities and was too costly to function.
The distribution of the picture from equal to equal (P2P) is one other widespread method to scale back the load to the document, in a unique infrastructure layer. It primarily reduces the load to the registration metadata, however remains to be topic to dangers of reliability talked about above. Later we additionally current the P2P layer to scale back the efficiency of the cloud storage output. In Databricks, we imagine that every layer should be optimized to offer reliability for all the battery.
Presentation of the Artifact Registry
We concluded that it was crucial to construct an optimized registration with out server to fulfill the necessities and ensure to remain forward of the speedy development of Databricks. Due to this fact, we construct artifact document: a container registration service of a number of clouds of personal harvest. The artifact document is designed with the next rules:
- All scale horizontally:
- Don’t use relational databases; As a substitute, metadata persevered in storage of objects within the cloud (an current dependence for manifest photos and layer storage). The objects of objects within the cloud are rather more scalable and have abstracted nicely within the clouds.
- Don’t use distant cache cases; The character of the service allowed us to retailer in cache successfully in reminiscence.
- Climb up/down in seconds: An intensive cache storage was added for BLOB picture and request manifestations to scale back the battle of the Sluggish Code (Registration) route. Because of this, just a few cases (equipped in a couple of seconds) should be added as a substitute of a whole bunch.
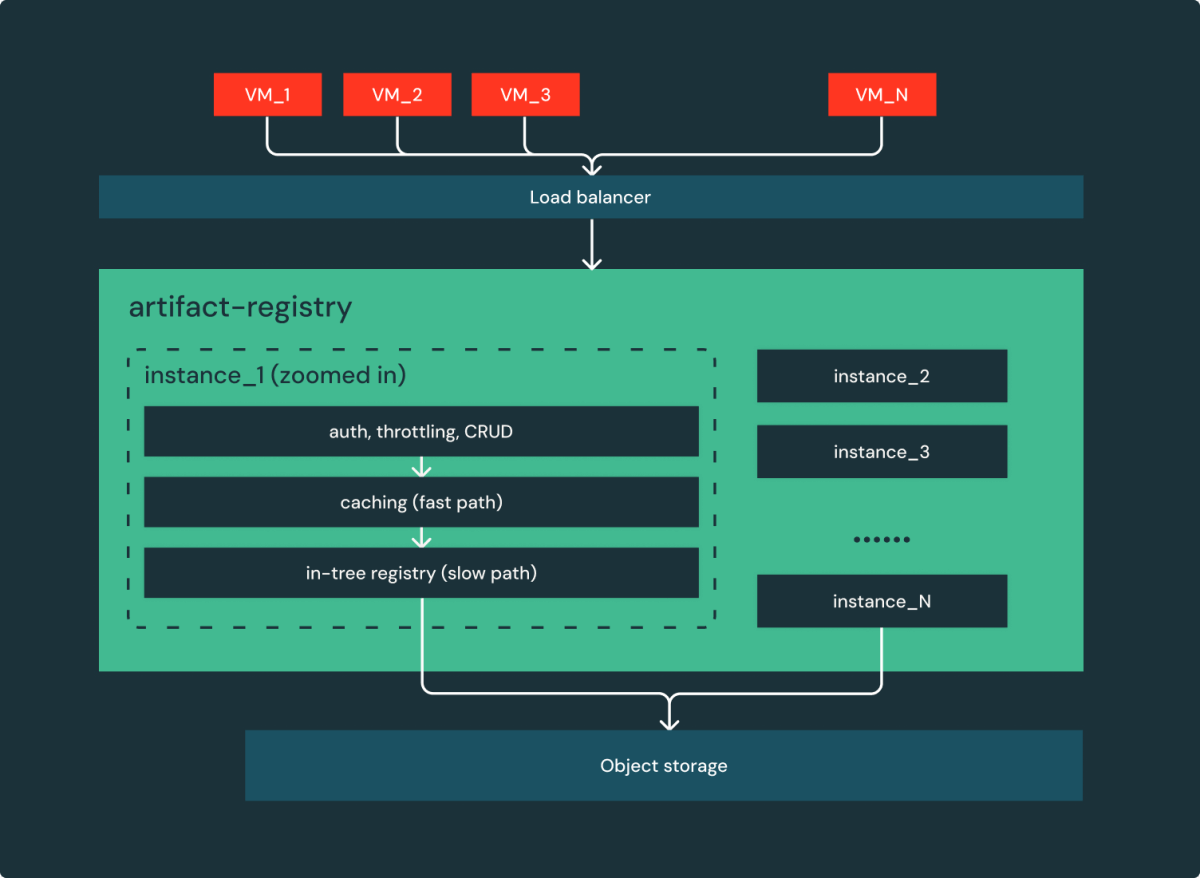
- Easy is dependable: Not like OSS, the information are of a number of elements and dependencies, the registration of artifacts covers minimalism. Behind the loading balancer, as proven in Determine 3, there is just one part and a cloud dependence (object storage). Certainly, it’s a easy and horizontally scalable internet service.
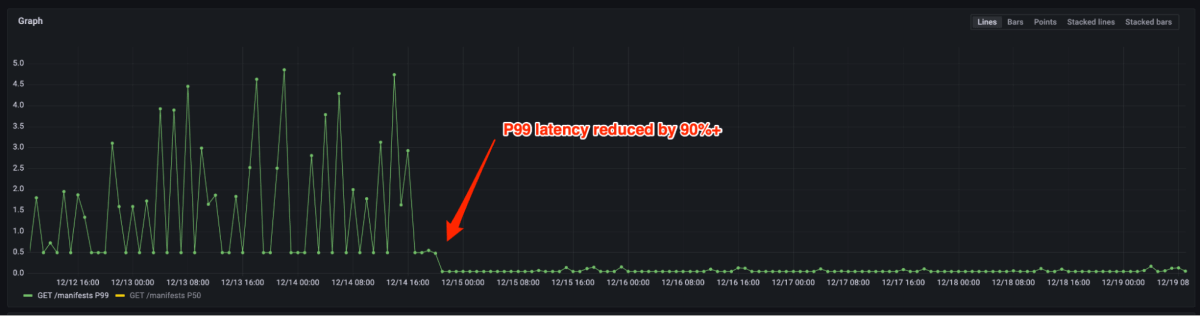
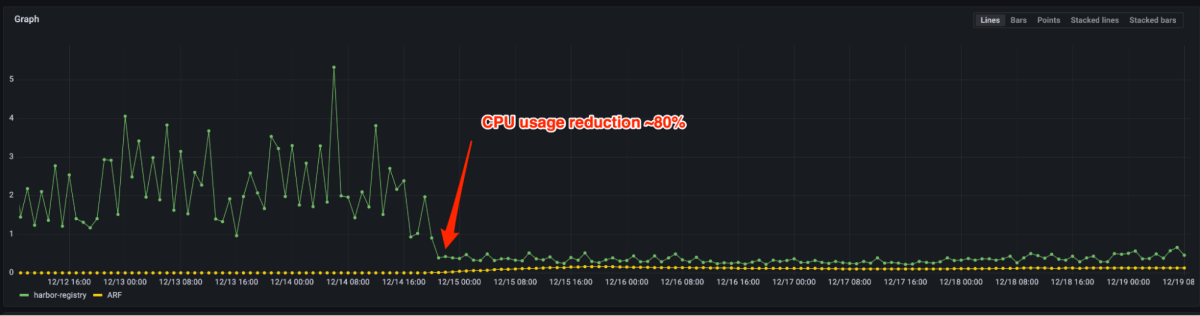
Determine 4 and 5 present that the latency of P99 was decreased by 90%+ and the usage of CPU was decreased by 80% after migrating from the open supply document to the artifact document. Now we solely want to provide some cases for a similar load in opposition to hundreds beforehand. In actual fact, the administration of most manufacturing site visitors doesn’t require scale typically. In case the automobile is activated, it may be finished in a couple of seconds.
Survivor
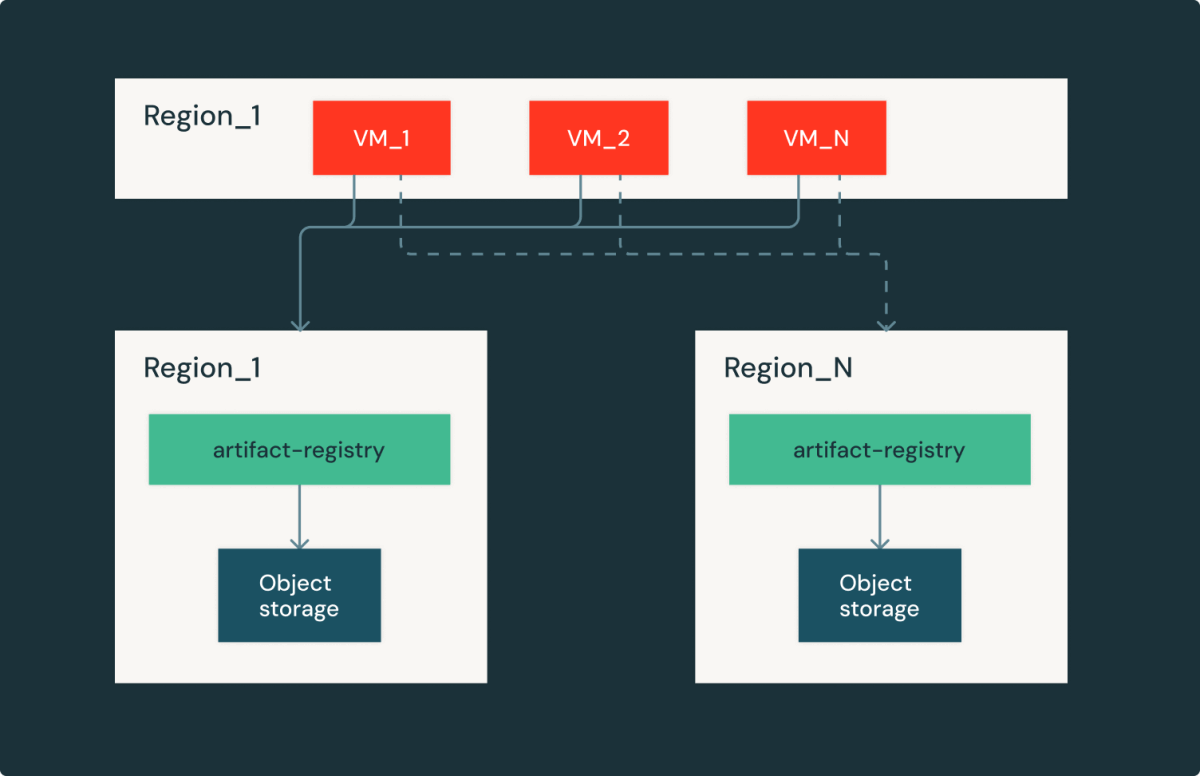
With all of the reliability enhancements talked about above, there may be nonetheless a failure mode that sometimes happens: storage interruptions of objects within the cloud. The storage of objects within the cloud are typically very dependable and scalable; Nevertheless, when they don’t seem to be accessible (generally for hours), regional interruptions are doubtlessly. In Databricks, we try to make failures in cloud models as clear as potential.
Artifact Registry is a regional service, an occasion in every cloud/area has an an identical duplicate. Within the case of regional storage interruptions, picture purchasers could fail in several areas with the compensation of picture discharge latency and the output price. By rigorously therapeutic latency and capability, we have been capable of rapidly get well from the interruptions of the cloud provider and proceed serving Databricks clients.
Conclusions
On this weblog publish, we share our journey to climb the container information from serving inside low rotation site visitors to the shopper that faces enriched work fees. We’re designing an optimized artifact document with out server. In comparison with the open supply document, it decreased the latency of P99 by 90% and the makes use of of sources by 80%. To additional enhance reliability, we feature out the system to tolerate regional interruptions of the cloud provider. We additionally migrate all instances for the usage of container information with out server current to the artifact registry. Right now, the artifact document continues to be a strong base that makes reliability, scalability and effectivity good in the midst of the speedy development of Databricks.
Recognition
The development of an infrastructure with out dependable and scalable server is a group effort of our foremost taxpayers: Robert Landlord, Tian Ouyang, Jin Dong and Siddharth Gupta. The weblog can also be a group work: we respect the views proportionate by Xinyang Ge and Rohit Jnagal.