

{kind=link}
Imaginative and prescient and language fashions (VLM) play an important position in multimodal duties resembling picture retrieval, captioning, and medical prognosis by aligning visible and linguistic information. Nonetheless, understanding denial in these fashions stays one of many major challenges. Negation is important for nuanced purposes, resembling distinguishing “a room with out home windows” from “a room with home windows.” Regardless of their advances, present VLMs fail to reliably interpret denial, severely limiting their effectiveness in high-risk domains resembling safety monitoring and healthcare. Addressing this problem is important to increase its applicability in real-world situations.
Present VLMs, resembling CLIP, use shared embedding areas to align visible and textual representations. Though these fashions excel at duties resembling multimodal retrieval and picture captioning, their efficiency drops dramatically in terms of negated utterances. This limitation arises attributable to biases within the pre-training information as a result of the coaching information units include primarily affirmative examples, resulting in an assertion bias, the place the fashions deal with affirmative and negated statements as equal. Present benchmarks, resembling CREPE and CC-Neg, are based mostly on simplistic examples with templates that don’t symbolize the richness and depth of negation in pure language. VLMs are likely to collapse adverse and affirmative subheading embeddings, making it extraordinarily tough to separate detailed variations between the ideas. This poses an issue in utilizing VLM for exact language understanding purposes, for instance querying a medical picture database with advanced inclusion and exclusion standards.
To deal with these limitations, researchers from MIT, Google DeepMind, and the College of Oxford proposed the NegBench framework for evaluating and bettering the understanding of denial about VLMs. The framework evaluates two elementary duties: Retrieval with Negation (Retrieval-Neg), which examines the mannequin’s means to retrieve pictures based on each affirmative and negated specs, resembling “a seashore with out individuals”, and A number of Selection Questions with Negation ( MCQ- Neg), which assesses nuanced understanding by requiring fashions to pick out applicable titles from slight variations. It makes use of enormous artificial datasets, resembling CC12M-NegCap and CC12M-NegMCQ, augmented with hundreds of thousands of captions containing a variety of denial situations. This can expose VLMs to adverse features and considerably difficult paraphrased captions, which can enhance the coaching and analysis of the fashions. Customary datasets, resembling COCO and MSR-VTT, together with negated subtitles and paraphrases, have been additionally tailored to additional increase linguistic variety and take a look at robustness. By incorporating different and sophisticated negation examples, NegBench successfully overcomes current limitations, considerably bettering mannequin efficiency and generalization.
NegBench leverages actual and artificial information units to check denial understanding. Knowledge units resembling COCO, VOC2007, and CheXpert have been tailored to incorporate denial situations, resembling “This picture consists of timber however no buildings.” For FAQs, templates resembling “This picture consists of A however not B” have been used together with paraphrased variations for variety. NegBench is additional complemented by the HardNeg-Syn dataset, the place pictures are synthesized to current pairs that differ from one another based mostly solely on the looks or absence of sure objects, constituting tough instances for understanding negation. The mannequin match was based mostly on two coaching goals. On the one hand, the lack of distinction facilitated the alignment between image-title pairs, bettering retrieval efficiency. However, the usage of a number of selection loss helped in making detailed negation judgments by preferring the proper headings within the context of the MCQ.

The fitted fashions confirmed appreciable enhancements on the retrieval and comprehension duties utilizing negation-enriched information units. For restoration, mannequin recall will increase by 10% for denied queries, the place efficiency is nearly on par with normal restoration duties. In multiple-choice query duties, enhancements in accuracy of as much as 40% have been reported, displaying an improved means to distinguish between delicate affirmative and adverse subtitles. Progress was constant throughout quite a lot of information units, together with COCO and MSR-VTT, and on artificial information units resembling HardNeg-Syn, the place the fashions appropriately dealt with negation and sophisticated linguistic developments. This implies that representing situations with varied forms of negation in coaching and testing is efficient in decreasing assertion bias and generalization.
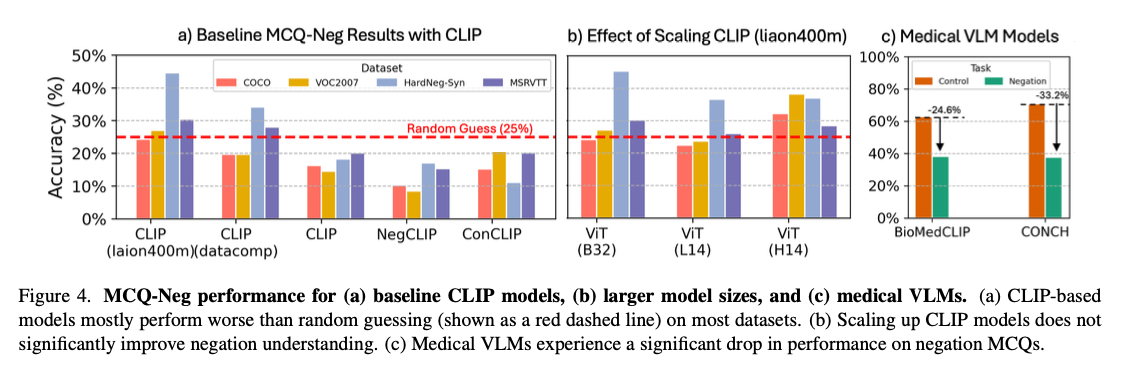
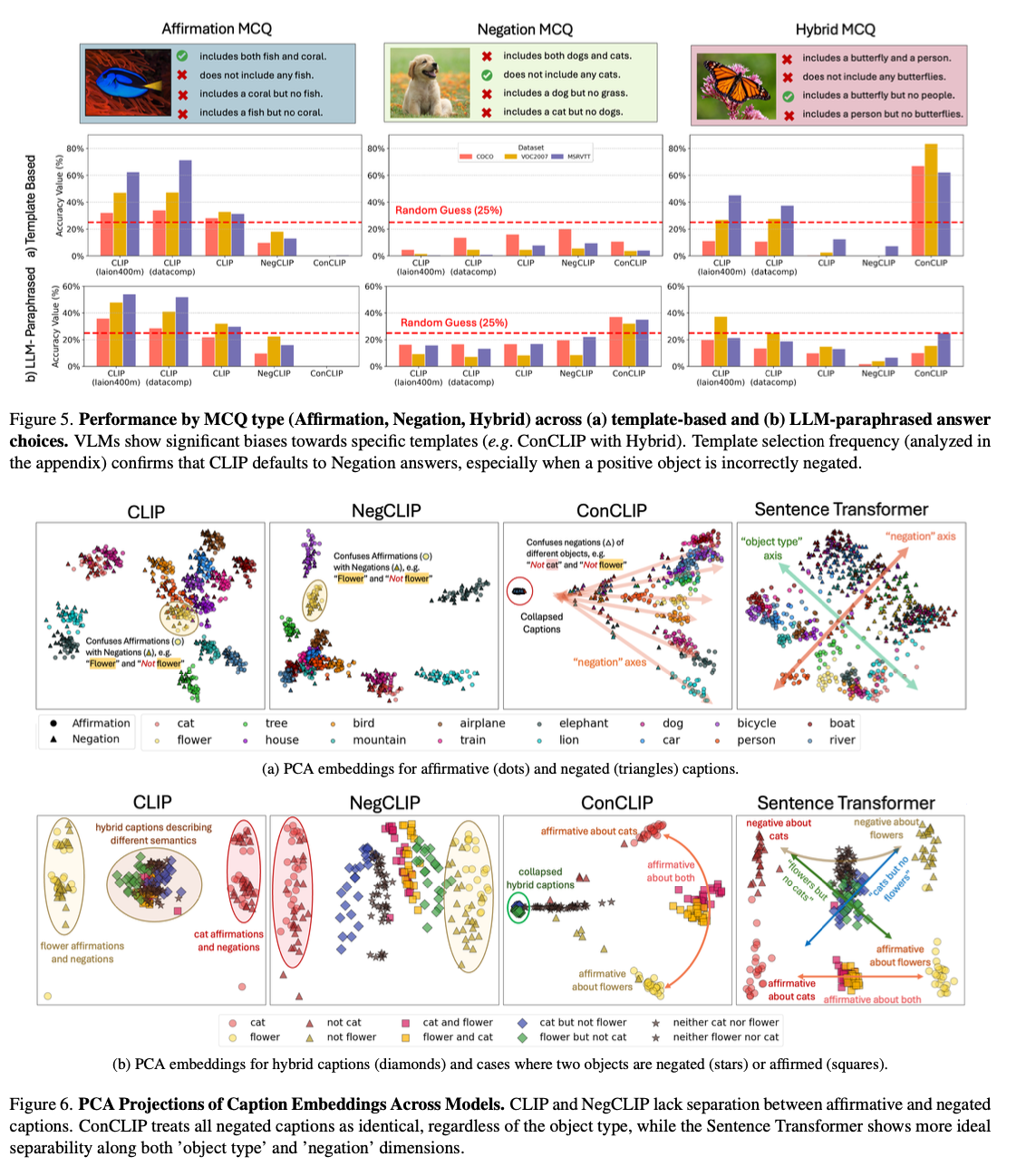
NegBench addresses a vital hole in VLMs by being the primary work to handle their lack of ability to grasp negation. It gives vital enhancements in restoration and comprehension duties by incorporating varied examples of negation in tr.AIning and analysis. These enhancements open avenues for far more strong AI methods which might be able to nuanced language understanding, with necessary implications for vital domains resembling medical prognosis and semantic content material retrieval.
Confirm he Paper and Code. All credit score for this analysis goes to the researchers of this challenge. Additionally, do not forget to observe us on Twitter and be a part of our Telegram channel and LinkedIn Grabove. Remember to hitch our SubReddit over 65,000 ml.
Aswin AK is a Consulting Intern at MarkTechPost. He’s pursuing his twin diploma from the Indian Institute of Know-how Kharagpur. He’s enthusiastic about information science and machine studying, and brings a powerful tutorial background and sensible expertise fixing real-life interdisciplinary challenges.