

{kind=link}
(Mohd.-Afuza/Shutterstock)
There’s something lurking in your file techniques and object shops. It is referred to as unstructured knowledge, and it is changing into an enormous mass that threatens to eat up storage prices, breach safety and privateness rules, and derail your AI initiatives. Is there any solution to conquer it?
Controlling this unstructured knowledge is changing into a prime administration precedence, for each offensive (GenAI) and defensive (regulatory) causes. However the very nature of unstructured knowledge makes it tough to handle. In any case, how are phrases and pictures labeled? How do you archive petabytes of log information? And maybe most significantly: how do you apply entry management throughout 1000’s of disparate knowledge silos?
The problem and alternative of managing unstructured knowledge is driving IT distributors to broaden their attain into the unstructured realm. A provider that has been floating in unstructured waters for a while is Knowledge dynamics. Piyush Mehta, a self-described “accounting finance man,” based the New Jersey software program firm in 2012 with the objective of addressing a number of the knowledge administration challenges he noticed firms battling.
The very first thing Mehta seen was that everybody appeared to have their very own definition of what “knowledge administration” meant.

Unstructured knowledge contains textual content, photographs, video, audio, IoT, and different file varieties.
“In the event you take a look at it from a CISO perspective, the query is, ‘How do I handle my knowledge threat?’” Mehta says. “In the event you discuss to the CDO, the query is, ‘Do I’ve a correct understanding of the classification and the method of how that knowledge is funneled to the proper location?’ After which in the event you take a look at it from a CIO perspective, it is lifecycle administration: How do I be sure I am provisioning the proper storage assets? How can I present and be certain that I’ve correct hygiene round when that knowledge is saved and the place and what we discover?
That siloization of information administration pondering results in a proliferation of information administration instruments. It is not unusual to see a single firm have 15 to 18 completely different level options to deal with varied facets of the info administration problem, from threat administration, classification or lifecycle, he says.
“And that turns into extraordinarily sophisticated,” he says. BigDATAwire in a current interview. “You’re scanning the identical knowledge a number of instances. That led us to say, hey, there have to be a greater approach.”
Massive Knowledge wave collapses
Within the previous days (i.e. the 2010s), all of us thought that one or two petabytes of information saved in a file system or object retailer was a giant deal. However that knowledge primarily resided on secondary storage. The actually necessary knowledge, the issues that drive enterprise functions and determination making, had been in block storage, on SANs that backed up the database.

Piyush Mehta is the CEO of Knowledge Dynamics
However issues have modified and at present there may be actually no distinction between block and file storage, says Mehta.
“There are high-performance functions that run with an object retailer on the again finish, as a result of it really works higher as a single flat layer from which to research knowledge,” he says. “It has hierarchical file techniques which might be extraordinarily quick and performance-ready.”
At this time, it isn’t unusual for purchasers to have a number of hundred petabytes of unstructured knowledge in file techniques and object storage, with tons of and billions of information or objects. These knowledge are distributed in geographical areas and in numerous storage matrices.
“And then you definitely add the cloud,” Mehta says. “So its stage of complexity and growth is gigantic and the management and context will depend on the place it’s situated, who it’s and what line of enterprise pertains to it.”
Managing that vast community of information and storage is tough sufficient. However once you add the disparate opinions of the CIO, the CDO, and the CIO, it turns into a convoluted mess. The argument for Knowledge Dynamics is that it may well assist handle all that unstructured knowledge unfold throughout disparate silos, whereas providing completely different capabilities to completely different customers and completely different use instances.
For instance, giant firms are particularly involved proper now in regards to the privateness and safety implications of mishandling that knowledge (as they need to be). However on the identical time, these monumental troves of unstructured knowledge are veritable knowledge gold mines, ready to be tapped with GenAI. Balancing that want to entry unstructured gold together with the will to maintain the corporate out of the protection of the Wall Road Journal for being a sufferer of the newest hack, is the true trick.
Unstructured knowledge processing
The large problem related to unstructured knowledge is that this knowledge just isn’t something good and structured, sitting in databases like SQL Server or Oracle, says Mehta. A lot of it’s generated by varied functions.
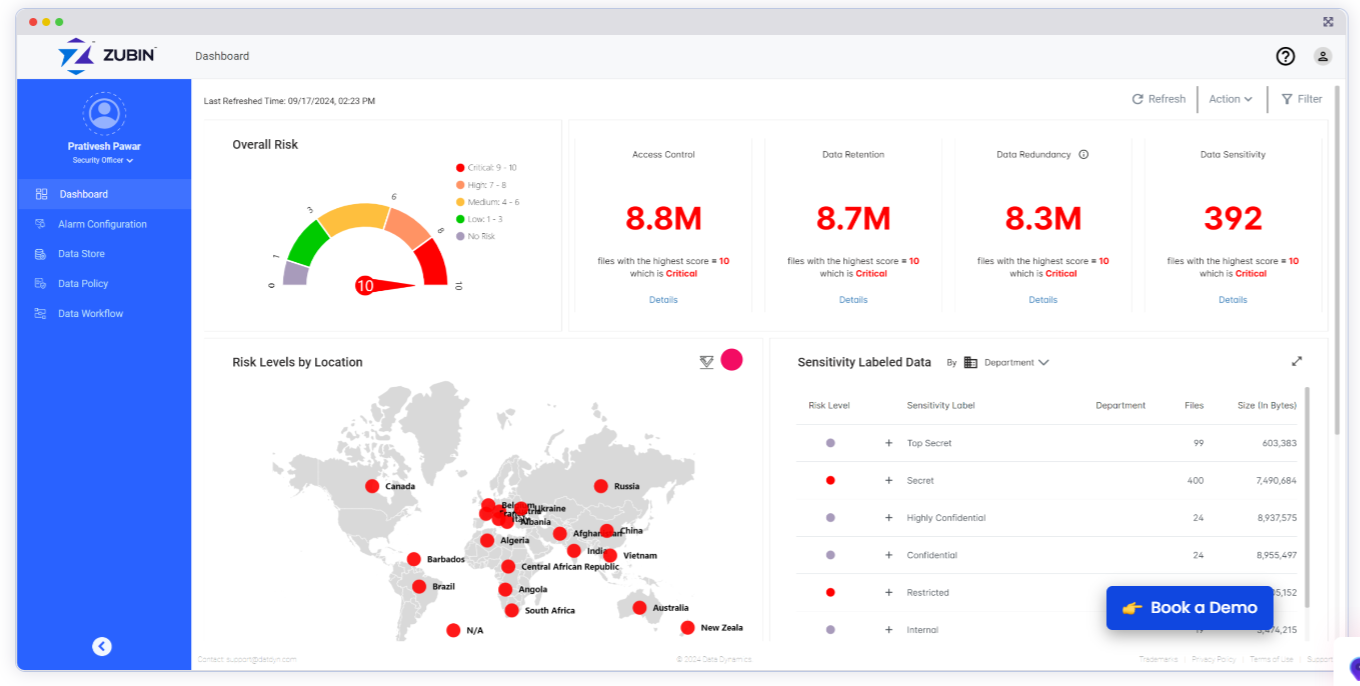
Zubin is Knowledge Dynamics’ newest product for managing unstructured knowledge
“They might be tick information which might be generated on this planet of finance,” he says. “They might be log information which might be generated throughout the board. It might be info from the IoT machine. They might be seismic information within the power world. “It might be affected person information or medical trial info or PACS (image archiving and communication techniques) photographs within the healthcare world.”
The primary Knowledge Dynamics product, referred to as Storage X, was primarily supposed emigrate this knowledge from one repository to a different. When Mehta realized that clients had been merely lifting and altering their knowledge, thus perpetuating the GIGO downside, he realized that higher evaluation was wanted. That led to the acquisition of a Pune, India, firm that developed a metadata evaluation device, which the corporate has expanded.
Metadata-driven analytics are wanted to achieve higher intelligence in regards to the knowledge that enterprises have saved in file techniques and object shops, together with NFS/SMB and S3-compatible object shops, in addition to storage choices. from suppliers, akin to microsoft share level, VAST Knowledge, NetApp, Delland Hitachi Vantara.
“Most of our enterprise clients have tons of of billions of information, so in the event you say, hey, I must open every file to see the content material, it should take fairly some time,” Mehta says. “So we ended up including one thing referred to as statistical sampling, which stated, ‘Hey, let’s select metadata as a filter after which be sensible about what we discover and what stage of precision it offers us when it comes to the content material we discover.’ We’re trying inside these information.’”![]()
As the corporate matured, it shifted its focus from optimizing storage and knowledge migration to democratizing knowledge. Its newest providing, referred to as Zubin, builds on earlier Knowledge Dynamics capabilities to offer its 300 clients the power to centrally handle insurance policies for disparate silos of unstructured knowledge.
As soon as the info is assessed on the company stage in Zubin, which was offered final monthIt’s as much as the person software or knowledge homeowners to outline which customers can entry that knowledge, by role-based entry management (RBAC). This offers clients the power to centrally outline knowledge administration throughout the spectrum of repositories, from native storage to cloud storage, whereas releasing up directors who’re nearer to customers to make choices about entry to knowledge.
The corporate has a theme, referred to as “Bytes to Rights,” that displays its concepts on the democratization of information.
“How is knowledge empowered?” says Mehta. “For us, that is an important factor as a result of we actually imagine that each firm is a custodian of the info they’ve, whether or not it is their individuals’s knowledge or their clients’ knowledge, during which case, how will we assist them grow to be higher custodians? ?”
Associated articles:
Selling knowledge sovereignty in a technology-driven world
Development of unstructured knowledge causes holes in IT budgets