
")
{kind=link}
Massive language fashions (LLMs) have demonstrated notable similarities to the power of human cognitive processes to kind abstractions and adapt to new conditions. Simply as people have traditionally made sense of complicated experiences by way of basic ideas reminiscent of physics and arithmetic, autoregressive transformers now show comparable capabilities by way of in-context studying (ICL). Current analysis has highlighted how these fashions can adapt to sophisticated duties with out parameter updates, suggesting the formation of inner abstractions just like human psychological fashions. Research have begun to discover the mechanistic facets of how pretrained LLMs characterize latent ideas as vectors of their representations. Nonetheless, questions stay in regards to the underlying causes for the existence of those job vectors and their various effectiveness throughout totally different duties.
Researchers have proposed a number of theoretical frameworks to grasp the mechanisms behind contextual studying in LLMs. One necessary method considers the ICL by way of a Bayesian framework, suggesting a two-stage algorithm that estimates posterior likelihood and chance. In parallel, research have recognized task-specific vectors in LLMs that may set off desired ICL behaviors. On the identical time, different analysis has revealed how these fashions encode ideas reminiscent of veracity, time, and area as linearly separable representations. By mechanistic interpretability strategies reminiscent of causal mediation evaluation and activation patches, researchers have begun to uncover how these ideas emerge in LLM representations and affect efficiency on subsequent ICL duties, demonstrating that Transformers implement totally different algorithms based mostly on inferred ideas.
Researchers from the Massachusetts Institute of Know-how and Inconceivable AI current the idea of encoding-decoding mechanism, offering a compelling rationalization of how transformers develop inner abstractions. Analysis on a small transformer educated on sparse linear regression duties reveals that idea encoding emerges because the mannequin learns to map totally different latent ideas into distinct, separable illustration areas. This course of operates at the side of the event of concept-specific ICL algorithms by way of idea decoding. Testing on a number of households of pretrained fashions, together with Llama-3.1 and Gemma-2 at totally different sizes, demonstrates that bigger language fashions exhibit this. encoding-decoding conduct idea when processing pure ICL duties. The analysis introduces Decodability of the idea as a geometrical measure of the formation of inner abstractions, displaying that earlier layers encode latent ideas, whereas later layers situation algorithms on these inferred ideas, and each processes develop interdependently.
The theoretical framework for understanding studying in context is essentially based mostly on a Bayesian perspective, which proposes that transformers implicitly infer latent variables from demonstrations earlier than producing responses. This course of operates in two totally different levels: inference of latent ideas and selective utility of algorithms. Experimental proof from artificial duties, significantly using sparse linear regression, demonstrates how this mechanism emerges throughout mannequin coaching. When educated on a number of duties with totally different underlying foundations, fashions develop totally different illustration areas for various ideas and on the identical time study to use concept-specific algorithms. Analysis reveals that ideas that share overlaps or correlations are likely to share representational subspaces, suggesting potential limitations in how fashions distinguish between associated duties in pure language processing.
The analysis gives compelling empirical validation of the idea encoding-decoding mechanism in pre-trained massive language fashions on totally different households and scales, together with Llama-3.1 and Gemma-2. By experiments with part-of-speech tagging and bitwise arithmetic duties, the researchers confirmed that the fashions develop extra distinct illustration areas for various ideas because the variety of examples in context will increase. The examine presents idea decodability (CD) as a metric to quantify how properly latent ideas will be inferred from representations, displaying that greater CD scores strongly correlate with higher job efficiency. Particularly, ideas regularly encountered throughout pre-training, reminiscent of nouns and primary arithmetic operations, present clearer separation in representational area in comparison with extra complicated ideas. The analysis additional demonstrates, by way of tuning experiments, that early layers play an important function in idea encoding, and modifications to those layers produce considerably higher efficiency enhancements than adjustments to later layers.
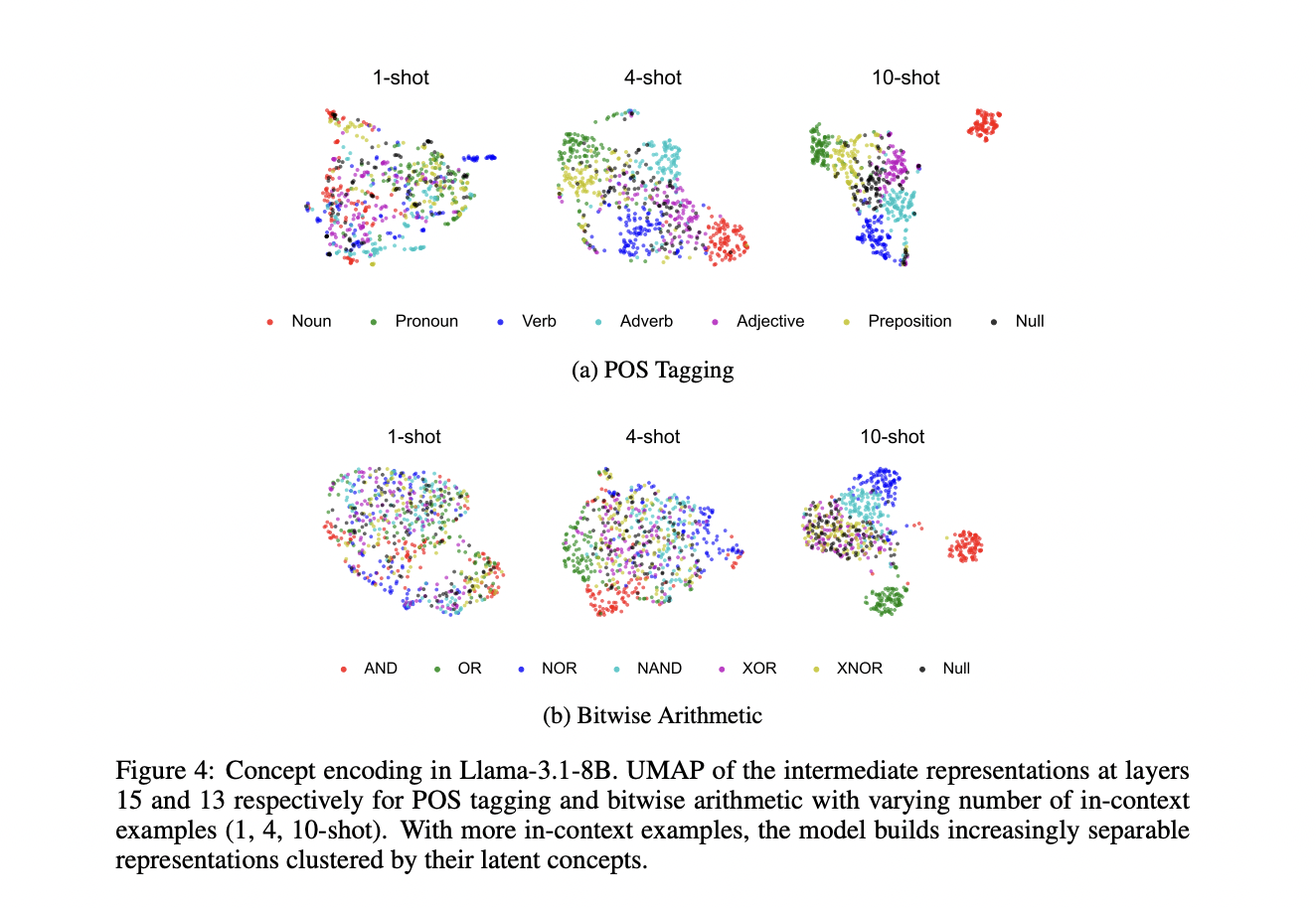

The idea of an encoding-decoding mechanism gives beneficial insights into a number of key questions in regards to the conduct and capabilities of enormous language fashions. The analysis addresses the totally different success charges of LLMs on totally different in-context studying duties, suggesting that efficiency bottlenecks might happen at each the idea inference stage and the decoding algorithms. The fashions present stronger efficiency with ideas regularly encountered throughout pre-training, reminiscent of primary logical operators, however can battle even with recognized algorithms if idea distinctions stay unclear. The mechanism additionally explains why specific modeling of latent variables doesn’t essentially outperform implicit studying in transformers, since commonplace transformers naturally develop efficient idea encoding capabilities. Moreover, this framework gives a theoretical basis for understanding activation-based interventions in LLM, suggesting that such strategies work by instantly influencing the encoded representations that information the mannequin era course of.
Confirm he Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, remember to observe us on Twitter and be part of our Telegram channel and LinkedIn Grabove. Remember to affix our SubReddit over 60,000 ml.
Asjad is an inner advisor at Marktechpost. He’s pursuing B.Tech in Mechanical Engineering from Indian Institute of Know-how, Kharagpur. Asjad is a machine studying and deep studying fanatic who’s at all times researching functions of machine studying in healthcare.